


Writing a book is a time consuming process, and if you’re going to dedicate a year, or more, of your life to it, it makes sense to pick the best tool for the job. If you’re technically inclined – and if you use Emacs – then the choice is obvious.
As I recently finished writing a book on Mastering Emacs I figured I would share my thoughts, and ideas, on how to write a book – specifically my own book – in Emacs.
The traditional way
The traditional model of publishing involves a Publisher; a Writer (that’s you); an Editor (a real human being); and, more often than not, Microsoft Word. There are many good reasons why a non-technical person would want to write a book in Word:
- It’s ubiquitous
So sharing documents is easy and so is finding a computer with any version of Word installed on it.
- Publishers and Editors expect it
It’s What Everyone Uses. So even though you really, really prefer your dinky old copy of WordSTAR — well, tough luck. They want your manuscript in Word anyway.
- It has a battery of features
And it’s not all bad, either. Spell- and grammar checking is excellent; the track changes and annotation functionality is handy; it’s WYSIWYG, so it’s easy for someone to format; and if you’re fancy, you can even diff documents.
The irony of course is that, once your manuscript’s written, a crack team of Santa’s Helpers spend days extricating your text from Word so they can typeset it in Adobe InDesign. It’s even funnier when you consider that a lot of techie-types will write the book in Markdown, docbook, or reStructuredText only to paste it into Word.
But that’s all beside the point.
When you write a book on Emacs it would be hypocritical not to use Emacs. Well, it so happens Emacs is the Right Choice for this anyway.
The Emacs Way
Picking a source format
When I decided to write the book I wanted it in both ePub and PDF format. My personal preference for technical books is PDF or print. But not everyone shares my enthusiasm for PDF files, so I also had to pick a toolchain that would allow me to output, at the very least, ePub.
The most obvious choice is LaTeX. Indeed, the final PDF output is typeset with LaTeX. But LaTeX is a rather baroque, and turing-complete, format; if you stray too far off the beaten path (or if you get too clever) the LaTeX-to-ePub generation would suffer. I’d have to reach in and manually fix things. Knowing how cumbersome mapping one source format to another can be, I decided not to write the book in LaTeX.
Ultimately I settled on reStructuredText. As a Python developer I knew it already, and as I have an aversion to Markdown – nobody can seemingly agree on a singular specification for that format – that ruled it out, even though it is far more ubiquitous.
So the idea was I’d write the book in reStructuredText and convert it to ePub and LaTeX using Pandoc.
Another option is, of course, Org mode. Unfortunately converting Org mode from one format to another made it difficult to work with. I could’ve exported Org mode as HTML, but like LaTeX there are many ways of doing the same thing. Plus, reStructuredText has a clearly-defined specification, and the docutils tool to fall back on if Pandoc failed me. I didn’t want the hassle of switching formats mid-way either, so I went with reStructuredText.
=============
First Steps
=============
.. epigraph::
I use Emacs, which might be thought of as a thermonuclear word processor.
-- Neal Stephenson, *In the Beginning… was the Command Line*.
...
In Emacs, there are several modifier keys you can use, each with its own character:
======== =========
Modifier Full Name
======== =========
``C-`` Control
``M-`` Meta ("Alt" on most keyboards)
``S-`` Shift
======== =========Here’s a snapshot of what the reStructuredText looks like. Very clean, and very readable, especially with syntax highlighting.
Proofreading and Tracking Changes
The next thing I had to worry about was proofreading. I wanted the book professionally edited, so I had to hire an editor. But I simultaneously didn’t want to deal with Microsoft Word.
Instead, I’d send the manuscript – the raw reStructuredText file – to the editor, and she would edit it as though it were her own manuscript. No track changes. If she had comments, she’d insert it above the paragraph, like so:
SUE: You should consider rewriting this paragraph.
When you use the command ``M-x toggle-truncate-lines`` [...]She still wanted to use Microsoft Word, so I inserted the raw text into a Word document, switched it to a fixed-width font, and told her to disable Word’s “helpful” AutoCorrect, as it’d mangle the reStructuredText formatting.
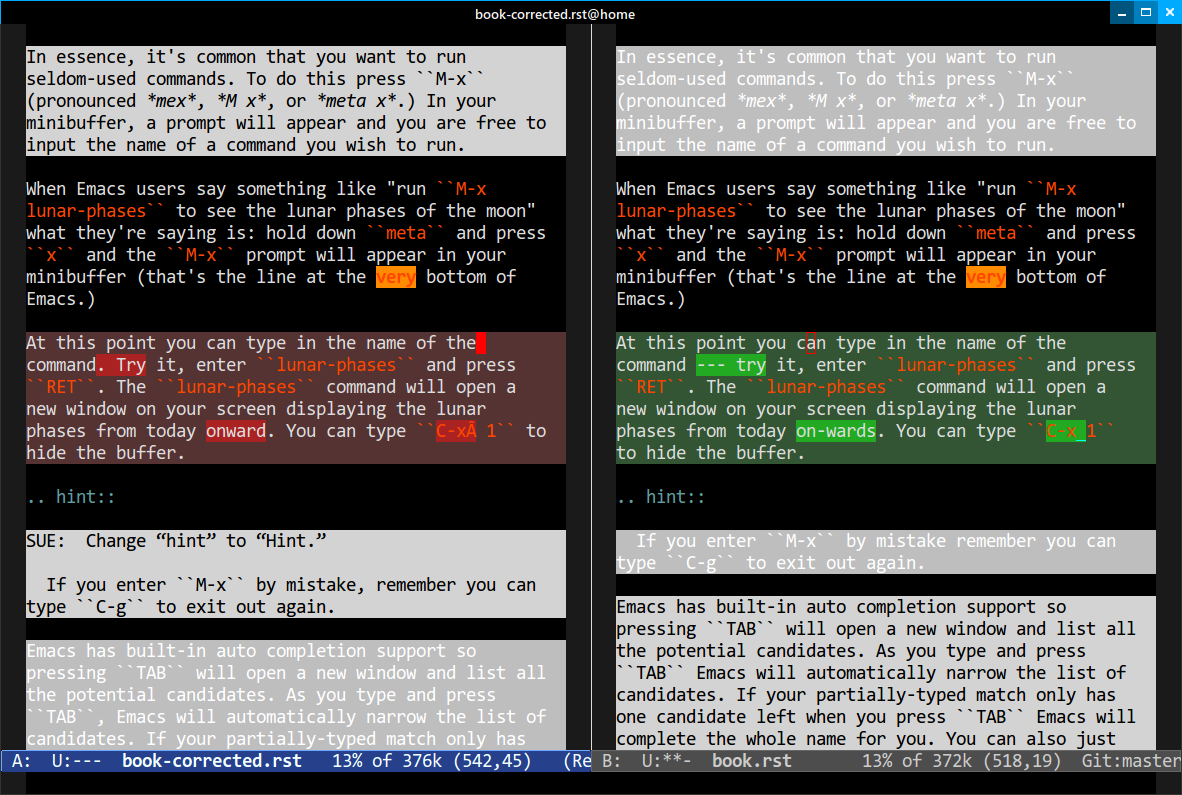
When she finished with the manuscript I’d use Emacs’s M-x ediff-buffers to ediff the corrected and original source manuscript, in effect using diff to track changes. Now you might be wondering: what about the comment paragraphs? Wouldn’t they screw up the diffing? Why yes, yes they would. But Emacs’s ediff is so advanced that you can tell it to hide regions match patterns by typing #h in the Ediff Control frame and enter the following regexp:
^SUE:And Emacs would disregard lines beginning with that pattern. Extremely useful, as I could read the comment and modify my manuscript according to the instructions given, while I also merged her changes. It’s hard to make out from the screenshot above that it works, and there were a couple of times it generated a too-complicated diff, but that took up maybe 10 minutes of my time, out of 4 hours or so of reviewing and merging her changes.
There were a few niggles such as the unicode character for NON-BREAKING SPACE not reading right, but I chalk that up to me using UTF-8 and her Windows machine using iso-8859-1. Again, with a regexp replace, fixing it took maybe 2 minutes. No problem.
So, all in all, I got to have my cake and eat it: I wrote the book in reStructuredText, had it proofread in reStructuredText, and corrected it in Emacs using ediff.
Spell Checking
This is one where I wish I had Microsoft Word. I used M-x flyspell-mode to track misspelled words as I type, and I tweaked aspell (the commandline spell checker Emacs uses in the background) so it’d use American English instead of my native UK English LOCALE:
.. -*- mode: rst; encoding: utf-8; ispell-dictionary: "american" -*-But aspell is an adequate, not great, spell checker. It’s fine for source code comments and minor README files, but for a book I found that it missed too many things, and used awkward hyphenation rules. Still, though, in the grand scheme of things it worked well. And being able to type C-M-i on a misspelled word and have Emacs auto correct it was certainly useful.
Jumping around
Jumping between chapters was very easy thanks to Helm’s M-x imenu support. M-x rst-mode builds an imenu index of all the chapters and sections, making cross-chapter navigation easy.
Pandoc
Pandoc’s great — it really is. But I still had no end of trouble with it. First of all, there is no documentation. There’s a man file and a smattering of examples and a few scattered blog posts explaining how to do basic things, but that’s it. You might be thinking: how much documentation does one need? It’s a converter. Well, when you’re trying to work out why certain formatting rules in reStructuredText aren’t applied in the LaTeX output, you do care. You care a great deal, in fact.
Ultimately I had to delve into the source to figure out why some things worked and other things did not. As it turns out, reStructuredText is not fully supported like its markup cousin, Markdown; or the red-headed stepchild of Markdown, Pandoc Markdown, Pandoc’s own take on Markdown.
I found this part exceptionally frustrating. That one format or the other is not equally supported is totally fine, but I wish they’d spelled out what it could and could not do. I may have picked a different source format had I known — or maybe not, who knows?
For instance, in reStructuredText you can annotate text with roles. There’s a handful in the specification, but I wanted one for small caps, like so:
:small-caps:`GNU`I discovered Pandoc converts everything into a kind of Abstract Syntax Tree in JSON format. So I was thinking: great, I’ll use Pandoc’s ability to call out to Python with each token from the AST and then hand-generate the LaTeX (and HTML for ePub) that I need. Nope. Not gonna happen.
It turns out that Pandoc “helpfully” strips roles and directives that it doesn’t recognize. So I figured: let’s hack the damn thing so it does what I need. But then I learn it’s written in Haskell. All right, I thought, the parser’s clean and easy to understand, let’s get a Haskell dev environment set up. Cue 900 MB of library cruft I had to download to even run the damn thing from source. I got flashbacks of bower, and npm, and the entire JS ecosystem and decided, in the end, to bard the reStructuredText source file with custom markers that I then map into LaTeX and HTML with sed.
Still, Pandoc’s a great tool, and I am glad it is there and that I got to use it. But although they support a wide variety of formats you best steer clear of all but the most maintained ones. Were I do to this all over again I would use docutils to spit out HTML (the LaTeX it generates is OK but not great) and then convert that to my target formats.
Outputting LaTeX
Or should I say, XeTeX. I needed XeTeX because the amount of METAFONT fonts available is vanishingly small. XeTeX also supports unicode, which is rather important when you want a PDF format that is as close to plain text as possible, for accessibility reasons.
XeTeX works great, and LaTeX is not a difficult thing to write. What is difficult is customizing LaTeX. Enabling old-style numerals (lowercase numbers) is easy enough, right up until you want to only enable them in some parts your book. Fact is, fiddling with LaTeX is time consuming but, to me, very important, so I spent the time needed to make it look as good as I could.
LaTeX is a great typesetting system, and I could make the book look even better if I had focused solely on PDF. As it stands, the lowest common denominator (ePub on Kindles, but more on that in a second) held it back. I wanted fancier tables and numbered, vectorized arrows that shows how the point moves through text instead of the simpler narrative format I adopted in the book. But I couldn’t do that in reStructuredText and Pandoc. A shame. Having said that, I am very happy with the PDF output. On a High DPI screen the book looks fantastic and I have received nothing but positive feedback so far.
Outputting ePub
An ePub file is a zip file with a CSS file, an image of the book cover, a metadata file and a bunch of HTML files. That’s it. And yet, I found it extremely hard to make it render properly on Kindles. To render HTML and CSS you need a browser engine, and unsurprisingly the engines on a lot of Kindles out there are pretty outdated and not very CSS compliant. Things like spacing between paragraphs instead of indented opening paragraphs vary. I cannot stand indented paragraphs and I went out of my way to disable it in the PDF version but it sadly lingers in some, but not all, Kindle readers. So converting to ePub is not a turnkey affair, even though it certainly seems that way from the outset.
I’m glad I added ePub support but it was a lot of work to make it look okay on old versions and good on new ones. So far, I’ve had no complaints. Touch wood.
Compiling the books
I use a simple Makefile to generate the output formats and in the case of LaTeX the intermediate .tex file so I can apply some sed scripts to it. From inside Emacs I used M-x compile to run the make command and display the output. The Makefile itself was obviously authored in Emacs also.
Combined with inotifywait in a Makefile rule I could seamlessly update the final deliverables as I typed. In the end I realized that I did not need that quick a turn-around on the output files as I am a habitual file saver and did that far more frequently than I reviewed the output. I could also do it with a save hook (or even an inotifywait hook) in Emacs.
With Emacs’s ability to browse PDF files I could review the book inside Emacs, next to the reStructuredText file, which came in handy occasionally.
General Editing
Throughout the course of writing the book I spent the entire time editing and moving and commands that work on sentences (M-e, M-a, M-k) and paragraphs (M-{, M-}) came in handy often. Part of what made my book editing less tedious was the elimination of superfluous stuff like fiddling with fonts and styling — a task relegated to simple markup in reStructuredText and settings defined by me for the actual typesetting itself.
I often found myself abusing certain turns of phrases and Emacs’s custom highlighting M-s h p would highlight, in garish black on yellow, such occurrences. The book was obviously stored in source control with Git and Magit.
On the whole, the entirety of the book, from conception as a series of notes and TODOs in Org mode, to the editing and merging of changes made by the proofreader took place in Emacs. The only tool I did not have in Emacs was Amazon’s Kindle Previewer tool.
Conclusion
Emacs is a great tool for book editing and writing. I used reStructuredText text but Markdown, ASCIIDoc, Docbook or any number of formats would work equally well. Emacs’s ediff is a powerful diffing tool that made it possible for me to track the changes made by the proofreader and selectively apply, but also edit, the changes she made before committing them to the original manuscript. I think that feature alone made it worth writing it in Emacs.
