


About a year ago I released an alpha – prototype, really – version of a tool I call Combobulate. I’d been using it personally for a while before I let it loose on the world, as I had been experimenting with tree-sitter, a library that parses source code and returns something called a concrete syntax tree. I’ve written about tree-sitter before. If you’re wondering why tree-sitter is so important and why Emacs is adopting it, then you should read tree-sitter and the complications of parsing languages where I explain why it’s such a big deal.
Combobulate takes the syntax tree created by tree-sitter and uses it to provide structured editing and movement. It can do it better than traditional, imperative or regexp-based approaches, because it has a perfect understanding of your code. That means there’s never any ambiguity as to whether { ... } is a statement block or an object in Javascript, for example.
That also means you can write code to do fancy things like move code around easily, or mark ever-larger tracts of text: first the string point is in; the assignment holding the string; then the function, and so on.
Because there is no ambiguity, it means you can automate things that were hitherto quite hard: like inserting a cursor at every element in an array for ease of bulk editing, daintily skipping over things that a regexp-based approach would mistakenly think of as an array element.
So, today, I’m here to talk about the new and much improved version of Combobulate which is available now.
Trees Made of Concrete
But before I get ahead of myself, let me briefly explain why a concrete syntax tree, the thing that tree-sitter spits out after reading your source code, is so important to all of this, and why Combobulate needs it to work well.
A concrete syntax tree is the nucleus of a computer program’s source code: it contains not only what a computer would need to interpret it, but all the bits that made up the code to begin with. So it is, unlike its svelte cousin the abstract syntax tree, capable of transforming back into the original source — more or less, anyway. (There are a couple of asterisks hitched to that claim.) Oh, and when I talk about a “computer program” and its “source code”, know that it needn’t be code: it could be Markdown, a config file format, or even a human language, if you’re sufficiently masochistic enough to try.
It’s a tree in its most literal form, too: a function definition has, for instance, the name and the arguments as leaves on its branch in the tree; ditto the body of the function, which in turn have more branches and leaves, and so on. Because it’s a tree, you can peruse how the bits join together (by the walking the tree as it’s called) and so you retain not only the syntax of the language but also the structure of your code. That means you can snip bits off the tree and be assured that, yes, all the child nodes of the function you snipped is, indeed, the whole function.
So syntax trees are useful — and also notoriously difficult to get right. There’s an art and a science to making them. To say nothing of putting them to use once you have them.
Your compiler is often the single source of truth for this, so why not just use that? Well, you could, but there’s a couple of snags. For instance, it is de facto against GNU policy for its compilers to give out that information: they have historically obscured and obfuscated the bits of the code that make it, to prevent dissemination. For languages created by commercial entities it’s more or less the same thing: it’s a commercially useful feature for their own IDEs, so they guard it jealously behind jumbo-sized EULAs or compiled code.
And now you know why syntax trees are rarely used outside of the interpreters and compilers for which they were created: they are hard to write and harder still to maintain.
Keeping this stuff hidden is not as important as it once was, and that is why there is a resurgence of tools and interest in this space. Don’t get me wrong: you don’t have to search far to find these things for a wide range of languages. What is hard is finding one tool with a panoply of complete grammars for common (and not so common) languages. If you’re in the business of text editors, you don’t want fifty different tools written in umpteen different languages. You want one tool.
That’s why the upcoming Emacs 29 ships with tree-sitter support. Tree-sitter has achieved that critical threshold where it’s expansive in its support of languages, and fast and stable enough to depend on.
But not only are the Emacs maintainers adding official support for tree-sitter – it remains, for now, an optional module – but they’re laying the groundwork for deprecating 40 years of regexp and elisp-based syntax highlighting (“fontifying”, in Emacs parlance) and indentation in favor of tree-sitter. For now, it’s opt-in; but over the years, as the tech matures in Emacs, this will surely change.
So What of Combobulate?
Well, if you’ve ever written Lisp in anger, you’ll no doubt have toyed with paredit, a tool that supercharges movement and editing of Lisp code. Paredit adds a plethora of razor sharp functions that can hack, slice and dice Lisp code.
Here’s a couple of examples:
;; When you type `M-r'
Before: (foo (a b c) (-!-d e f))
After: (foo (a b c) -!-d)
;; When you type `M-s'
Before: (foo (a b c) (-!-d e f))
After: (foo (a b c) -!-d e f)
;; When you type `M-<up>' once, then twice.
Before: (foo (a b c) (d -!-e f))
First: (foo (a b c) -!-e f)
Second: -!-e fIt can do way more than that, so that’s just a brief taste of what it can do. All it does is push and pull brackets around. It’s rather good at it, too.
I cannot write elisp without it: it’s that essential. It’s also why I wrote Combobulate. I want this in other languages: I want better movement, and better editing.
But… without the aforementioned concrete syntax tree, it is practically impossible to do this reliably. I’ve tried. You need a lot of regexp; a lot of brittle code; and endless patience!
The only reason paredit – which has been around for decades, at this point – is capable of doing all of this, is because in Lisp, the concrete syntax tree is the code! That is one of the greatest things about Lisp. (It helps that Emacs has a wealth of code that can understand parentheses-based languages.)
But now that tree-sitter is a thing, I wrote Combobulate to sate my own needs for precision editing and movement.
Now, ah… most languages aren’t as syntactically simple as Lisp. Lisp is homoiconic, a rare and unique concept in programming languages today. It has few “moving parts” in its language design. So, of course, it’s not possible to perfectly capture the simplicity and power of editing and moving around in Lisp and apply it elsewhere. Just look at C++, a language that no one would ever dare call simple to its face.
Instead of deifying something that cannot be faithfully reproduced, I want Combobulate to capture the spirit of paredit instead. That’s more achievable.
I spent quite a long time thinking about it, and I’ve decided on a few key principles I want Combobulate to abide by:
- Enrich Emacs’s existing concept of movement and editing
-
That means navigating by defun, word, list, and sexp is as important in Combobulate as it is in vanilla Emacs.
Moving around by sexp is especially important to me, as the notion of what that is depends heavily on syntactic context, but also the language.
Once you’re used to editing and moving using primitives – like word, sentence, paragraph, defun, and sexp – you want them to work consistently, and predictably, in other major modes as well. Marking, killing and moving must all work in harmony. As much as possible, anyway.
(And if you’re unsure what the deal is with all of that, and what moving by defun or sexp means and why I care so much, then I have a great book for you.)
- Predictability
-
One of the hallmark features of navigating and editing with constructs like
C-M-fandC-M-kis the predictability of it all. I know, before I’ve even typed the key, where my point will be at the end of it.In modes I use infrequently, where I have not internalized this, I tend to get frustrated when the commands misbehave due to limitations in the major mode or my understanding of how it should work. Doubly so when you can immediately spot, with your own eyes, the right place it ought to go to.
Third-party packages (and a few builtin ones…) frequently screw this up and it’s a never-ending source of frustration.
This is part of the reason why I never liked moving by line number or by reductive and “automatic” systems that generate places for you to jump to or edit. If I cannot predict ahead of time what I need to type to maintain the tempo of editing and movement, then I find tools that do this to hinder more than they help.
However, I understand lots of people do like that workflow, and I’ve made sure Combobulate accommodates it also, thanks to opt-in support for things like Avy.
- Configurability
-
Everyone’s different, and the ergonomics of movement and editing (entwined as they are in Emacs) is also highly personal.
That is why Combobulate’s movement and editing routines are, by and large, as configurable as I can make them. I’ve also spent a significant amount of time trying to make it simple. Or as simple as you can make an inherently complex topic, anyway.
If you want to move by opening and closing tags in JSX and not by the whole thing, then simply change the variable that governs sexp-based navigation. If you want
C-M-a(go to beginning of defun) to include, or exclude, arrow functions in Javascript and lambdas in Python then no problem. There’s a variable that you edit that controls this.If you’d prefer your “expand region” – that selectively expands ever-greater tracts of syntactic constructs in your code – to include or exclude certain nodes, then no problem. There’s a variable you can tweak. Or maybe you want custom command that only marks certain things.
The choice is yours.
- Extensibility
-
I’ve written Combobulate in such a way that it is reasonably easy to control how Combobulate determines what is navigable and what is editable.
And if you dislike how Combobulate does it, you can leverage its builtin tools and make it do what you want it to.
That’s the Emacs way of doing things.
Here’s some example code that navigates to the next dictionary, list or set:
(defun move-to-next-container () (interactive) (with-navigation-nodes (:nodes '("dictionary" "set" "list")) (combobulate-visual-move-to-node (combobulate-nav-logical-next) t)))
A Brief Tour of Combobulate
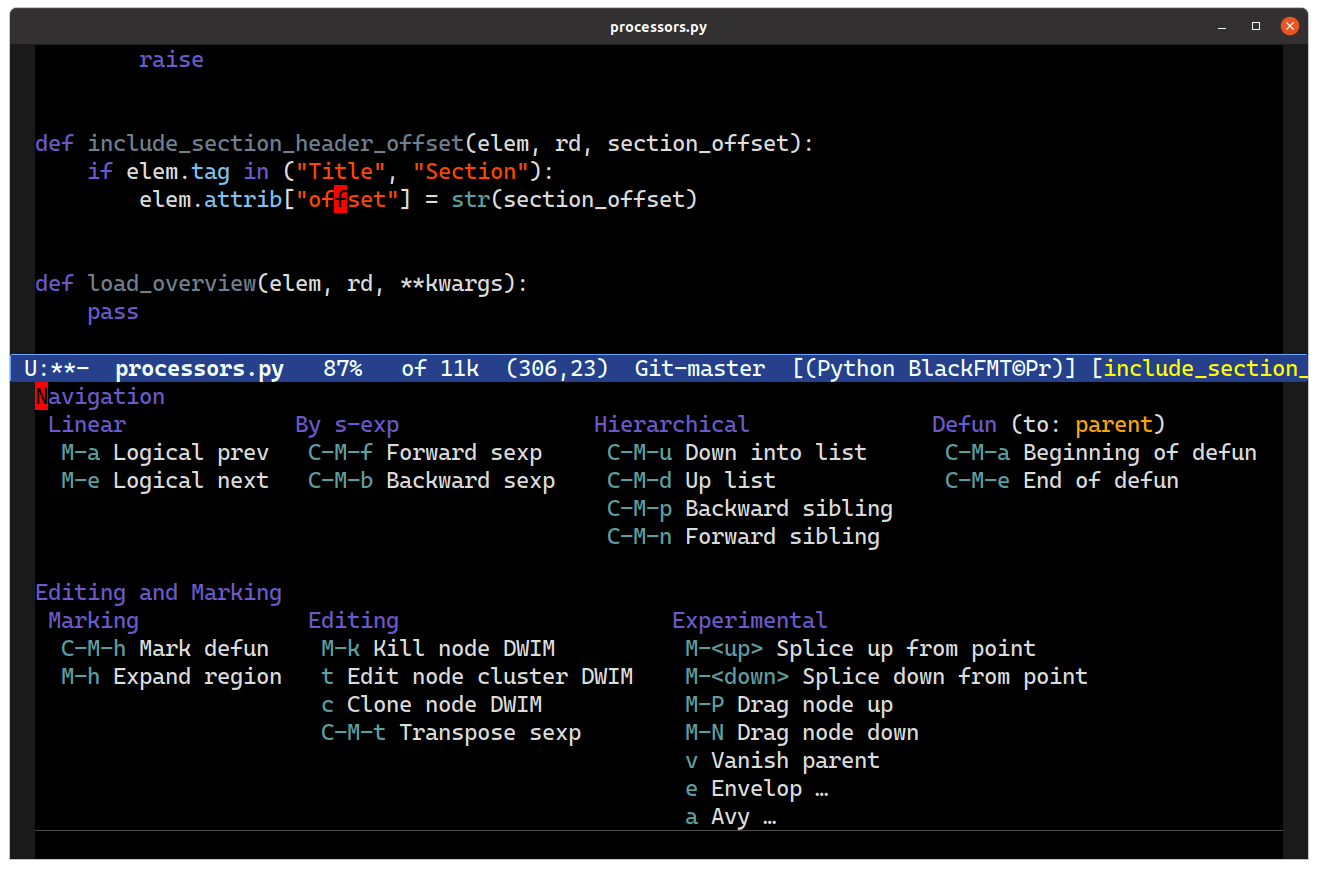
Here’s a whistle stop tour of what Combobulate can do. There’s so much more to do: but it’s already rather feature rich and guaranteed to improve your productivity over what your major mode would ordinarily provide.
Where to get Combobulate
You can find Combobulate, along with installation instructions, on Combobulate’s Github page.
How it Works
Combobulate is a minor mode. All of its features are tied to, and set up, when you enable it. Combobulate must support the language you want to use it with; and in turn, you must have a valid tree-sitter grammar installed for that language also. When Combobulate’s minor mode is enabled, it supplants many of the default Emacs key bindings with Combobulate’s own that, to the best of my ability, are sympathetic improvements to the existing ones.
In addition to that, there’s a prefix key map bound to C-c o that exposes a large array of additional key bindings and commands. Because it’s difficult to get used to new and complex packages, Combobulate also has a transient UI (see above) with all the key bindings and commands available to you. It’s bound to C-c o o by default; however, it’s optional. Everything in the transient UI is also bound to the prefix key C-c o or to the minor mode key map in combobulate-mode.
Combobulate has a large array of variables that intrepid elisp hackers can amend at their leisure to change how Combobulate behaves. I have made what I think are sensible defaults: they should work well for most people out of the box. But you can extend and amend Combobulate to suit your needs (but more on how in a later article.)
Presently, Combobulate supports: Javascript+JSX, Typescript+TSX, YAML, Python, and CSS. But extending it to new languages is doable for someone with a passing familiarity with tree-sitter.
Structured Editing
Splicing
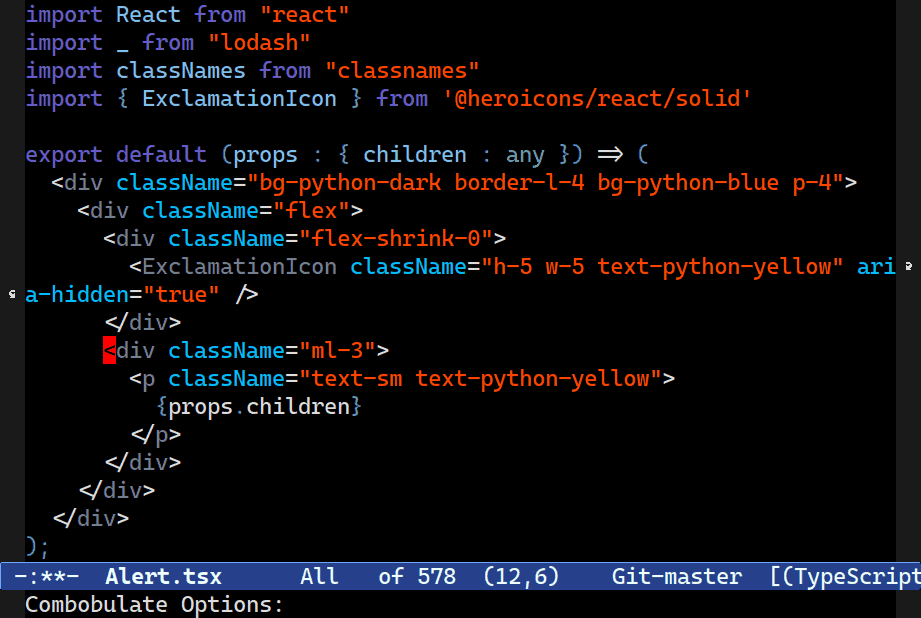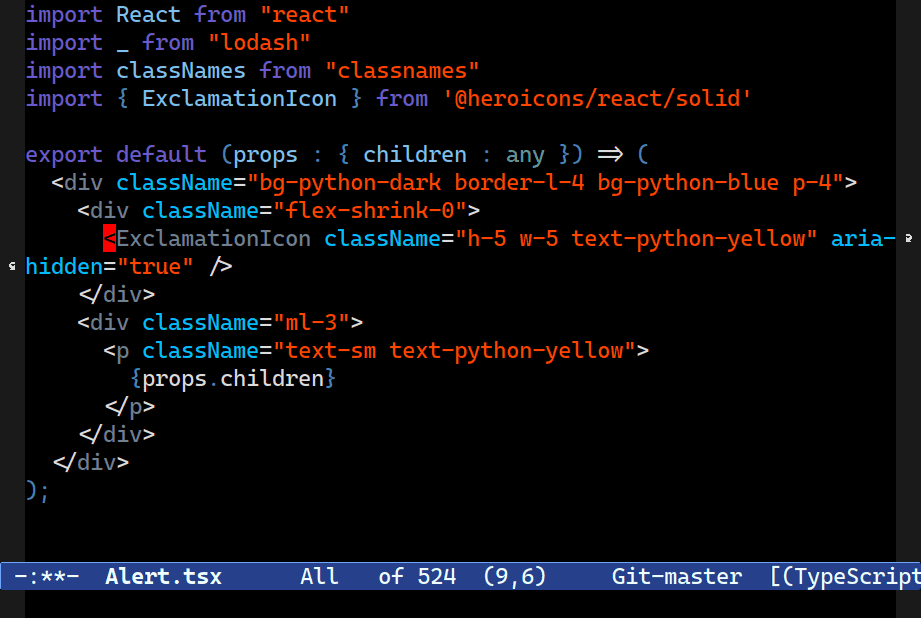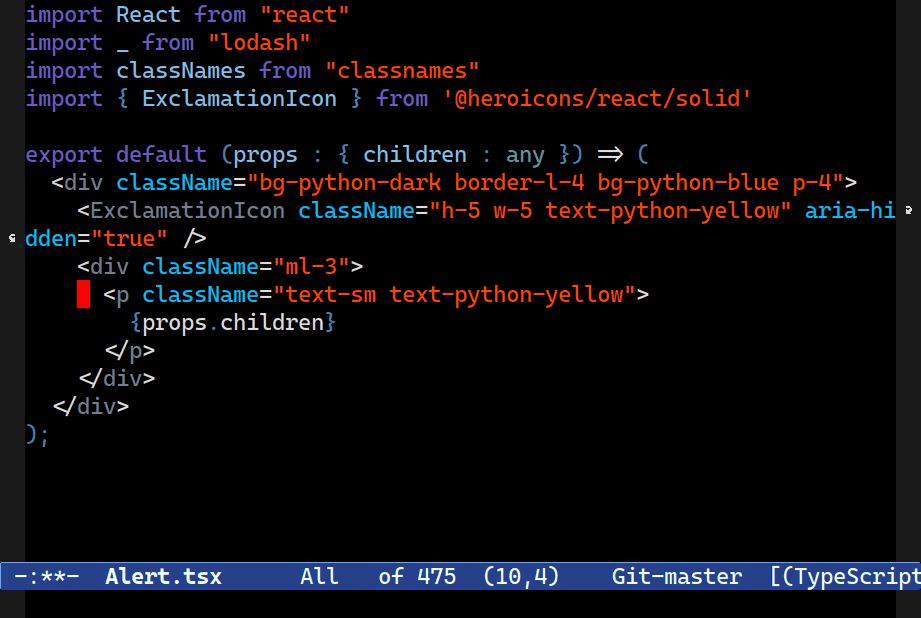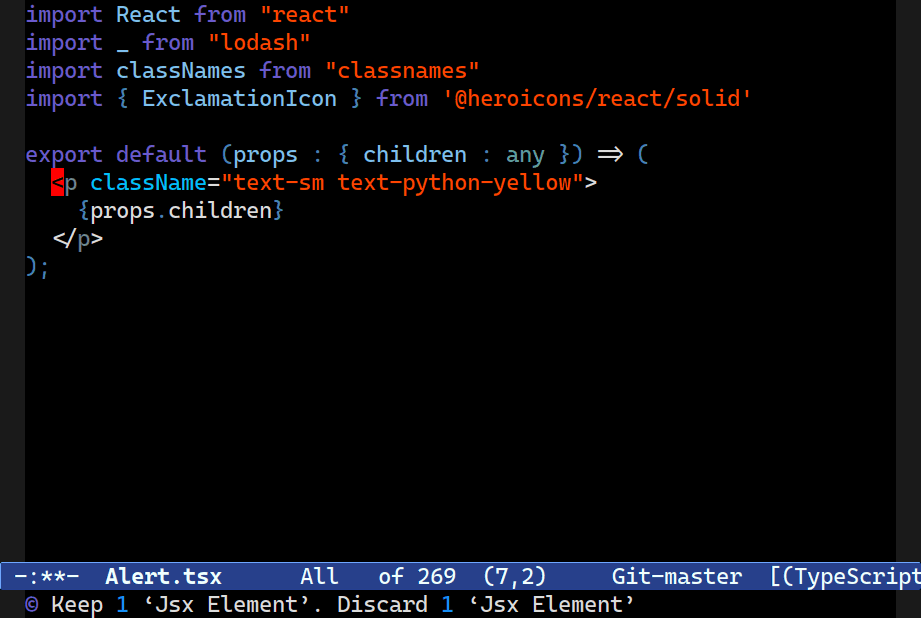
C-M-[<up>/<down>] splices up out of the structure you're in, preserving statements after (or before) point. A useful tool for surgically keeping and discarding parts of your code.Combobulate will try to splice code into the surrounding structure, preserving your formatting (where possible.) It’s designed for precision editing where you want to keep certain elements of your code before or after point, and discard the rest.
It’s also an experimental feature. Combobulate uses a rather crude and ham-fisted approach to this; there are severe limitations on how or where it can work, and how well.
It is also, unequivocally, one of the harder things to get right without manipulating the concrete syntax tree and rebuilding the source from the now-modified tree. There is a good reason why I am not doing it that way, but I will save that for a later article.
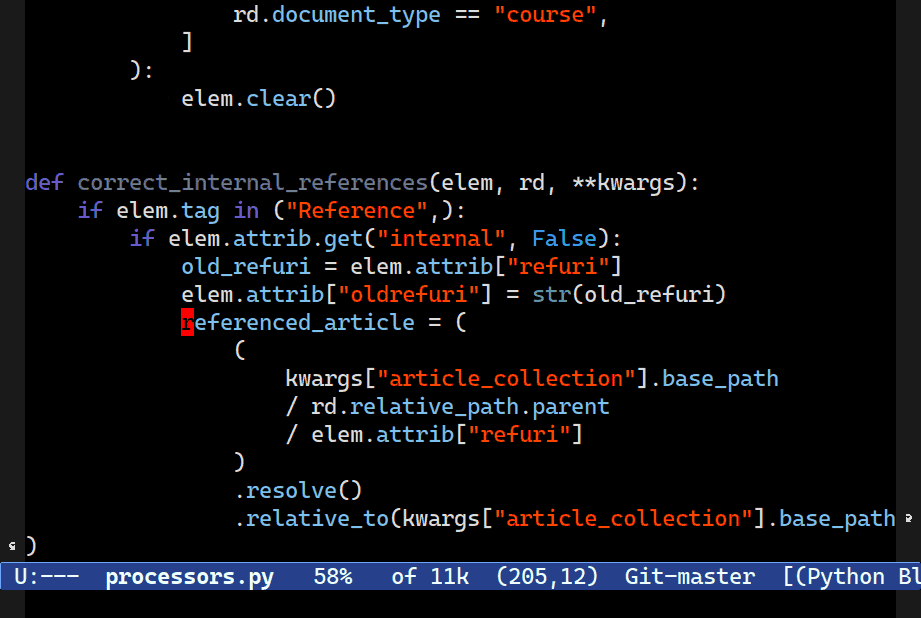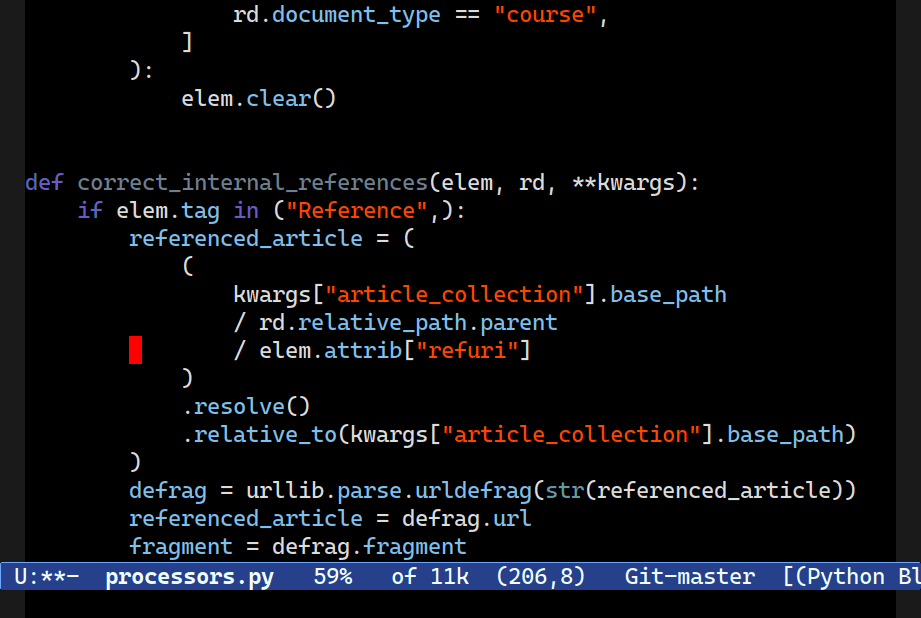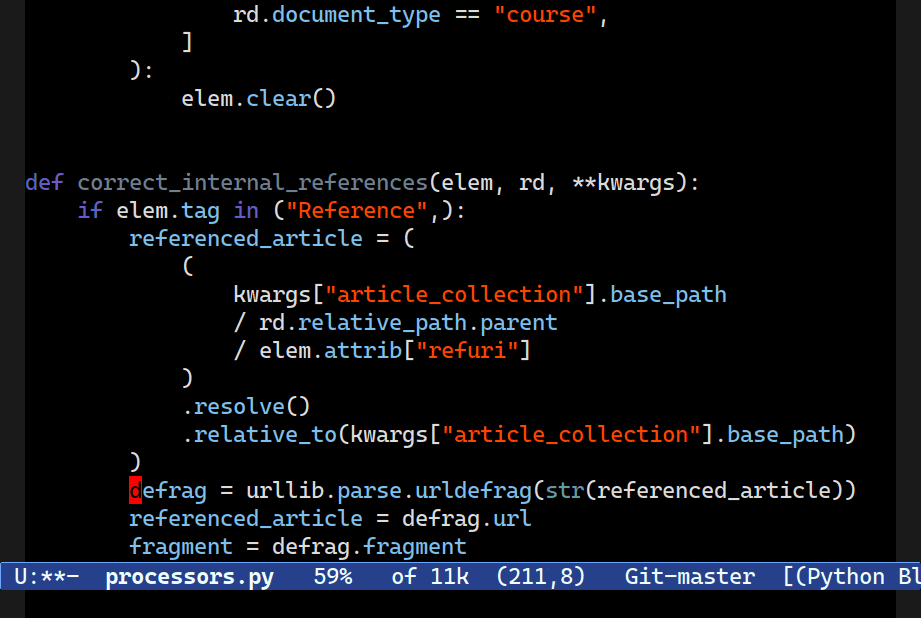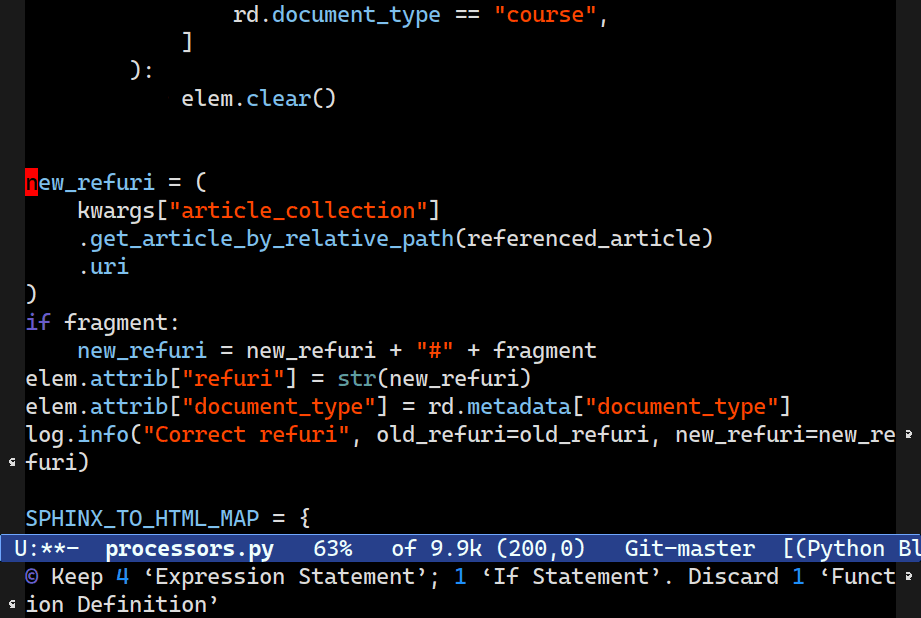
C-M-<up> and C-M-<down> splice code around point and up into the structure above. C-c o v instead keeps everything at the level your point is at, but it vanishes the parent node.
Dragging
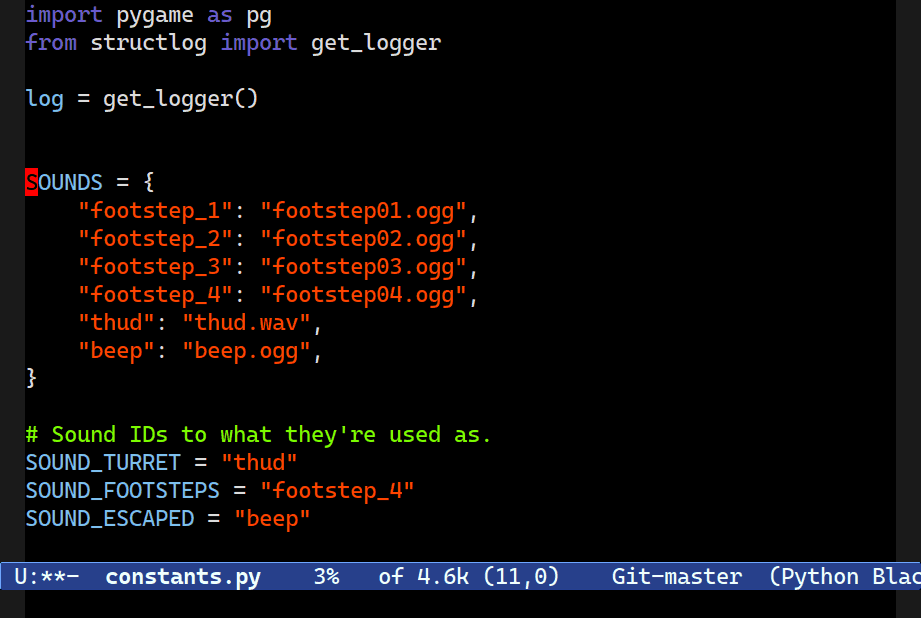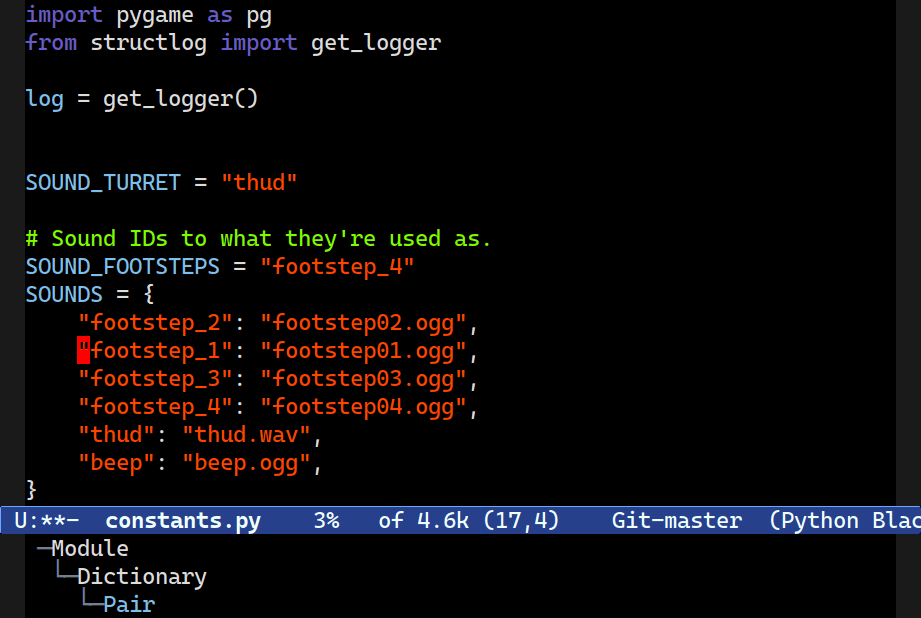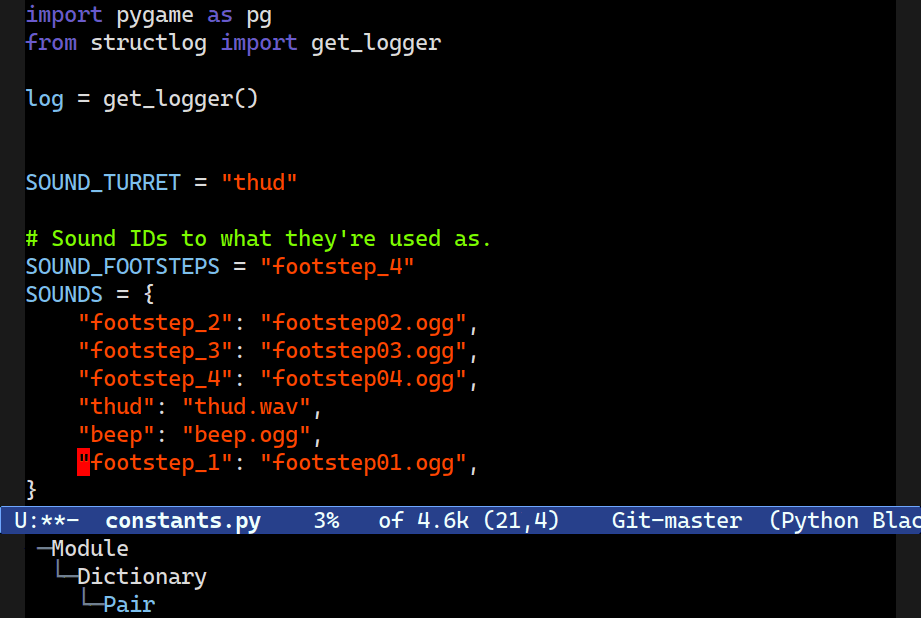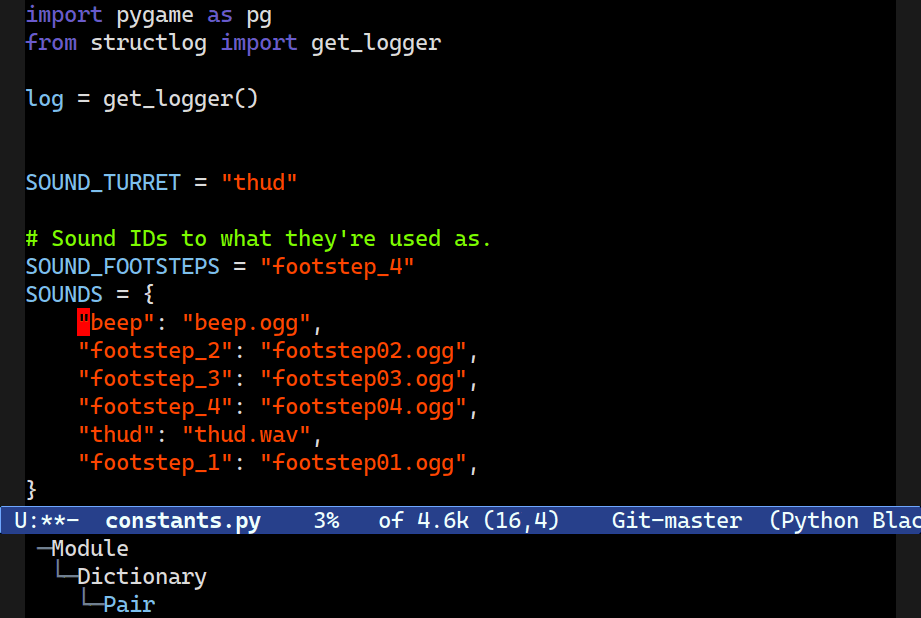
M-S-[n/p].Dragging – transposing two sibling nodes – is another useful feature of Combobulate. It works in a wide range of contexts, and it’ll carefully swap two nodes, preserving their formatting and indentation.
Multiple Cursors
C-c o tMultiple Cursors is a great package and Combobulate will optionally support it if you have it installed. Combobulate will DWIM (Do What I Mean) when you invoke C-c o t. If you’re in a dictionary, it’ll insert cursors for all the pairs; ditto for function arguments, JSX attributes, open/close elements, and so on.
Cloning
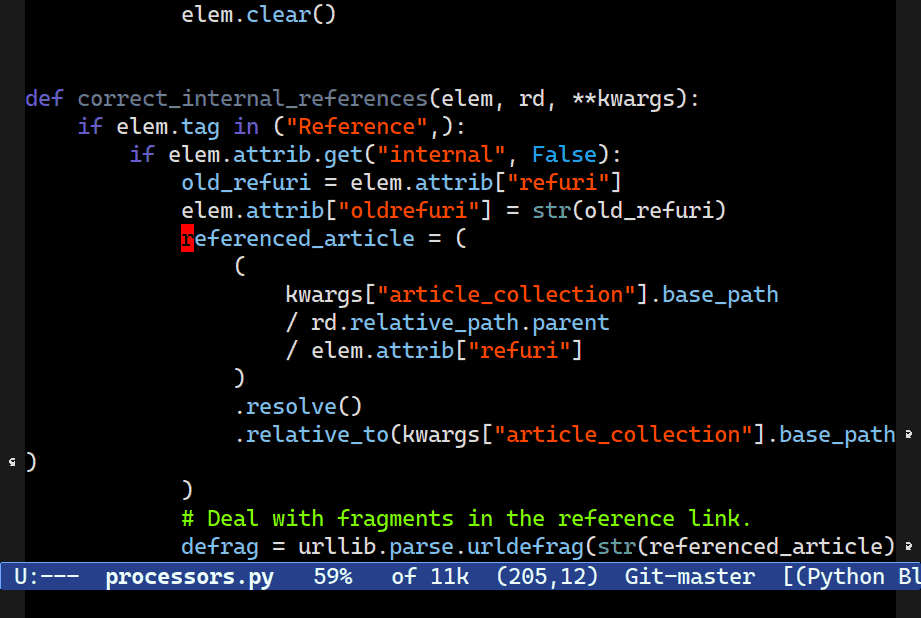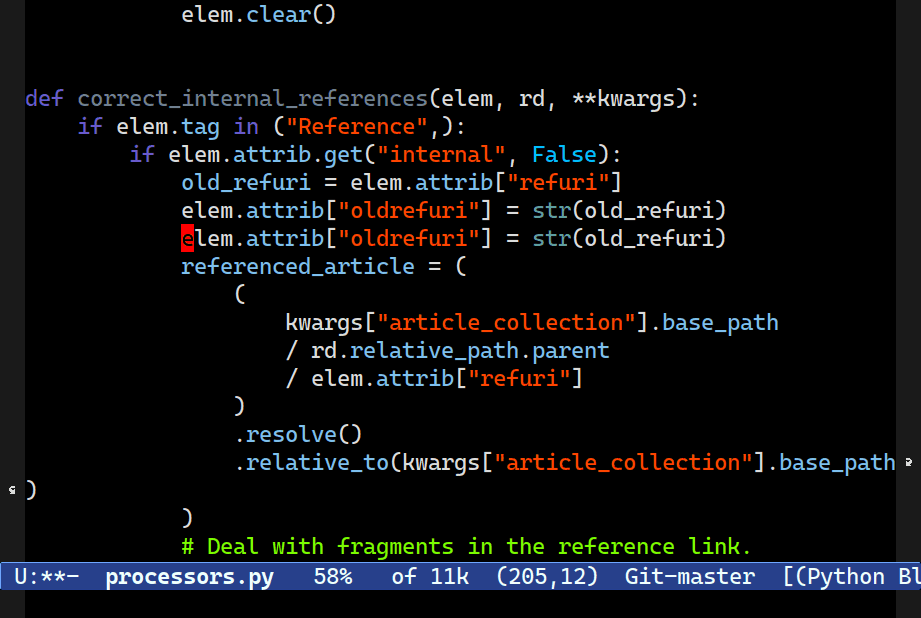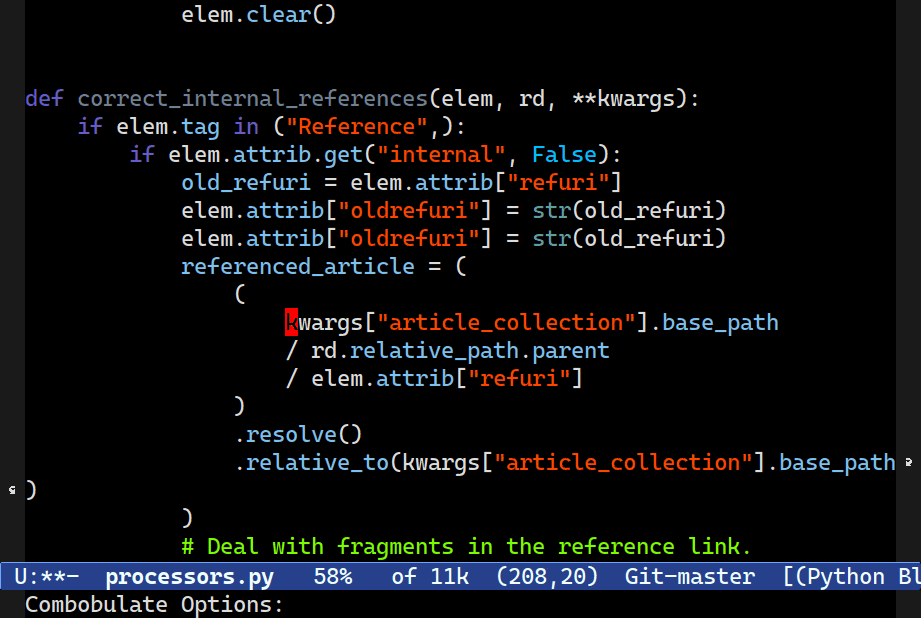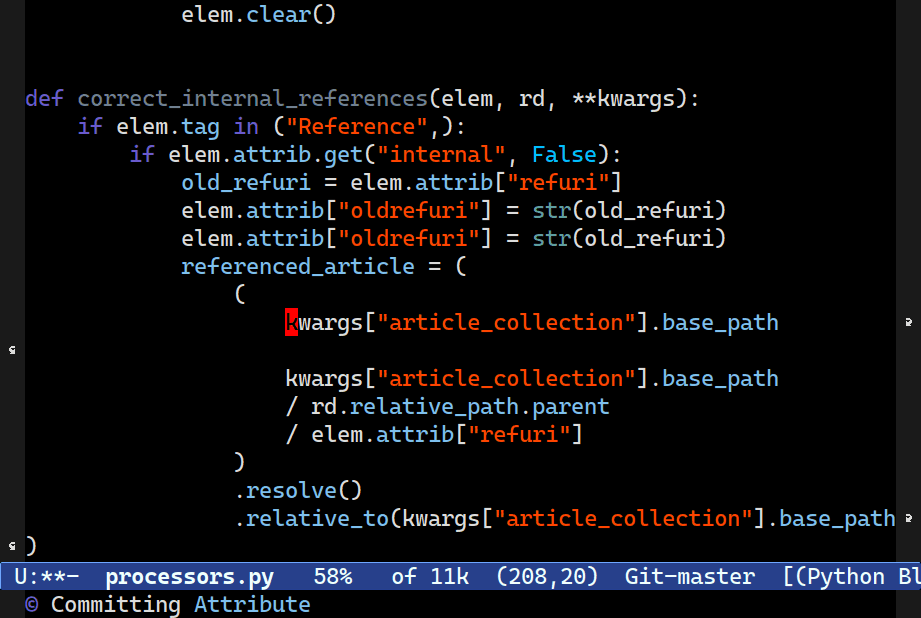
C-c o c clones the node at point. If the choice of node is ambiguous, you're presented with a selection interface where you can choose the one you want.Duplicating code is common activity — and often tedious, particularly if the structure is complex or tricky to select. Combobulate can duplicate the node at point. If there are ambiguities, such as multiple nodes that start at the same place (which is common), then Combobulate will ask which of the nodes present you wish to copy.
Enveloping
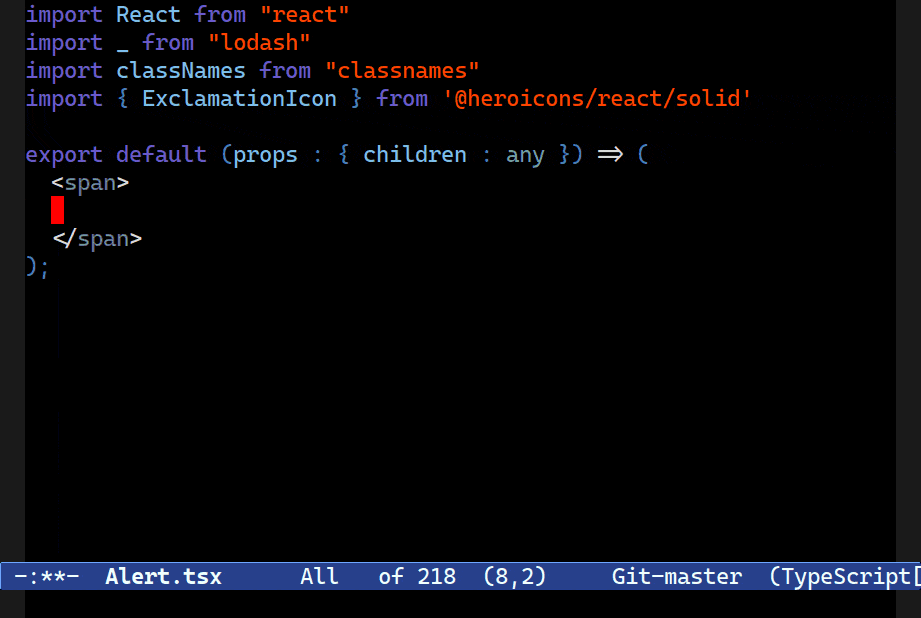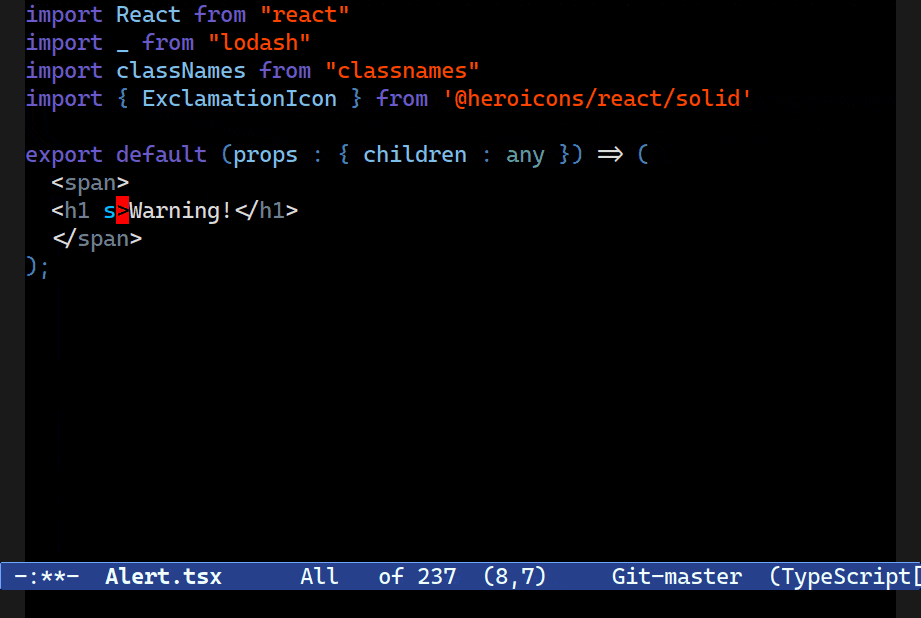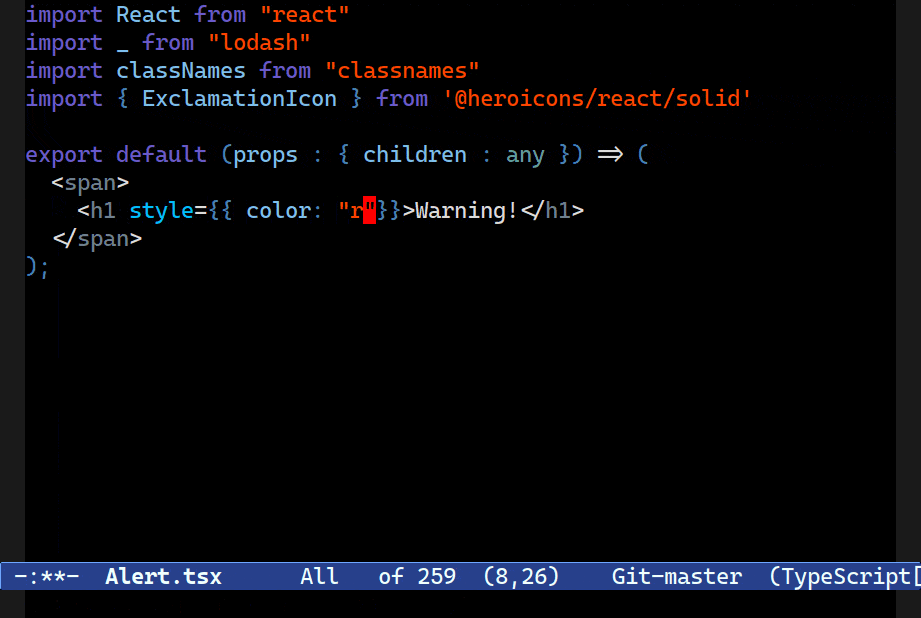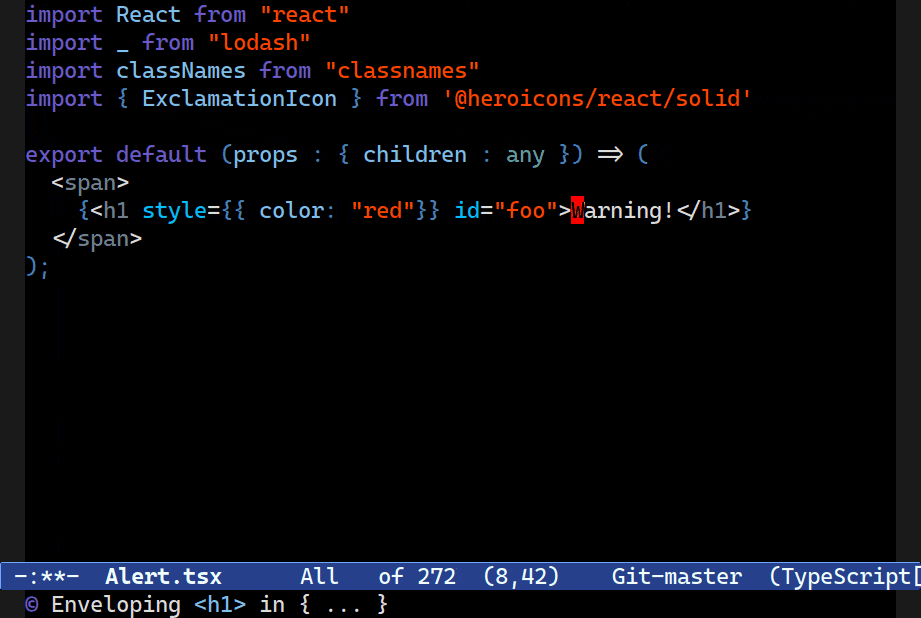
style attribute and a string for the id attribute.Combobulate comes with simple code templates called envelopes. Combobulate’s envelopes only activate in the right place: expanding a JSX tag won’t work if you’re not in a place where inserting such a tag is legal, for example.
They’re also used to augment things like inserting the correct attribute value combination as the example above demonstrates.
Combobulate’s envelopes are found in C-c o e C-h or C-c o o e.
Language-specific Features
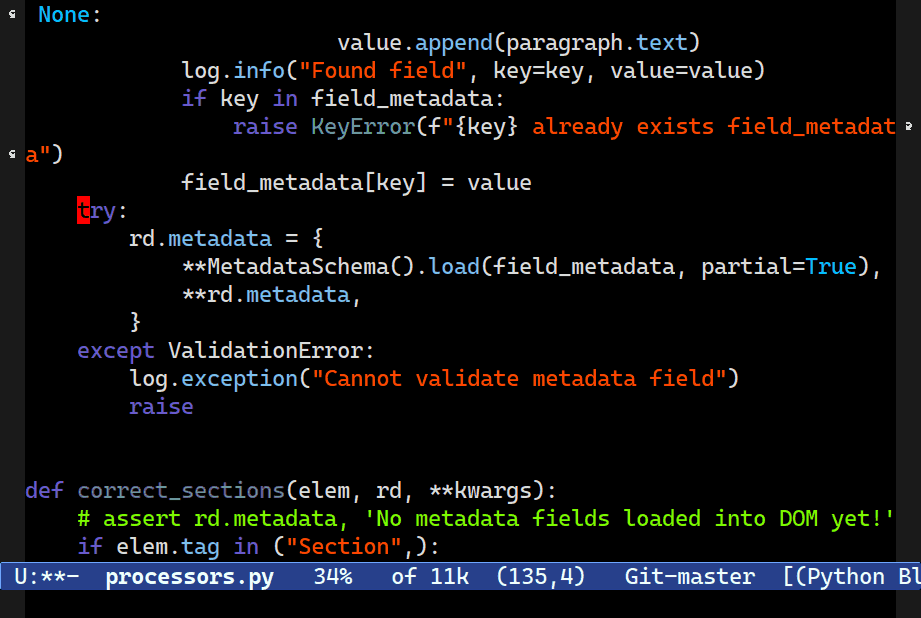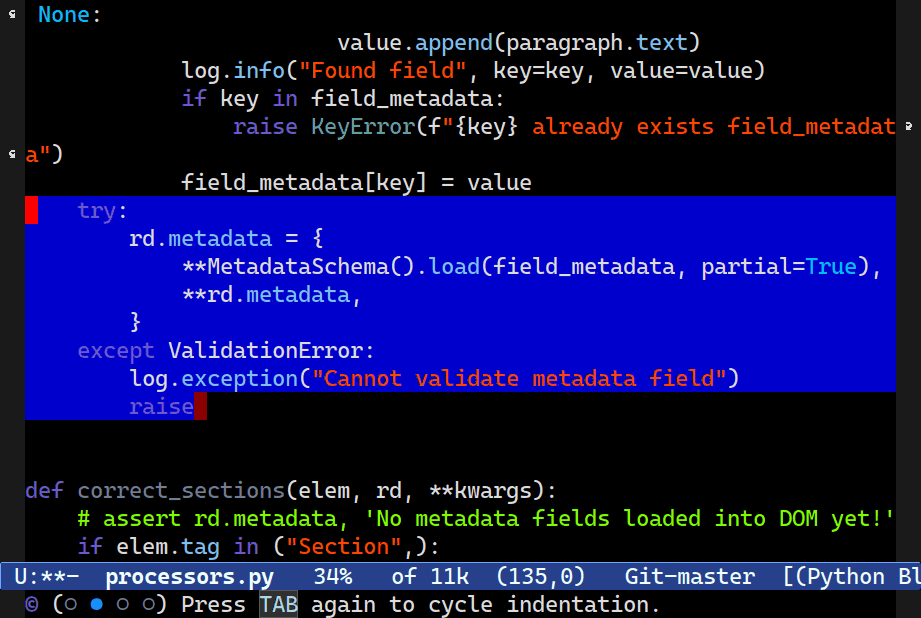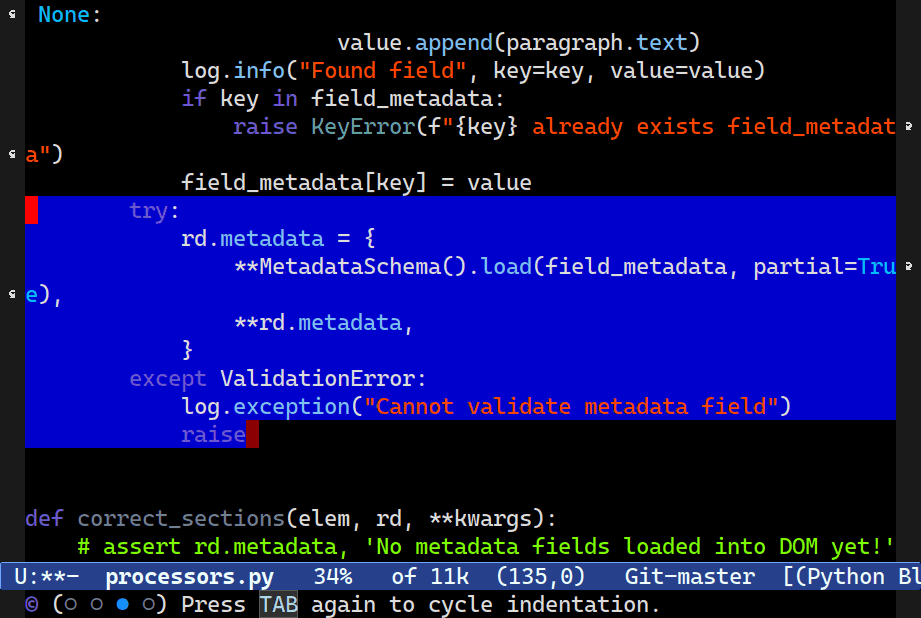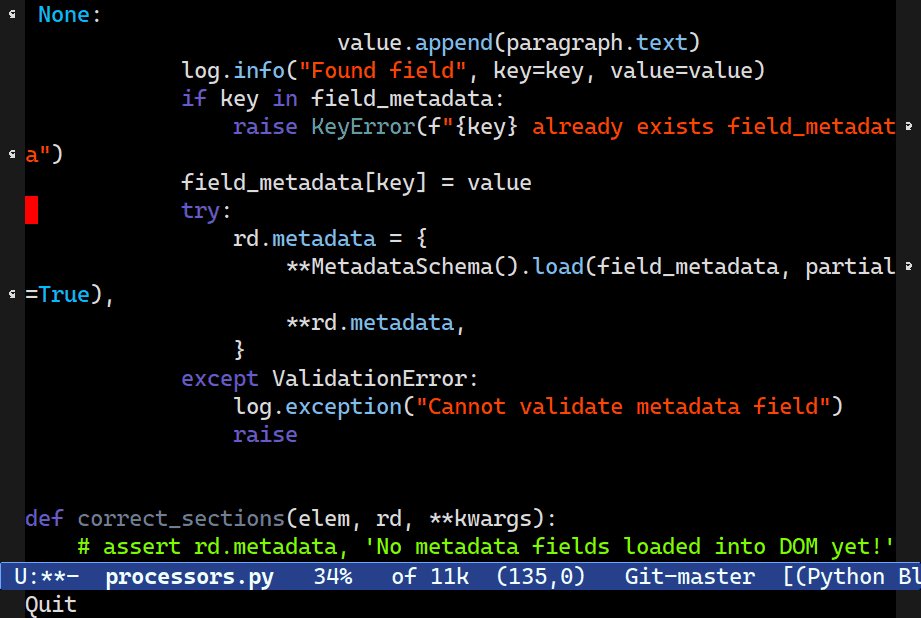
TAB now indents the block at point.I’ve also added a number of mode-specific helpers, particularly the ability to auto-complete tags in JSX, or inserting the right attribute type in a JSX attribute.
Hitting TAB on a statement in Python now indents the whole thing: you can cycle through the indentation easily by repeatedly pressing TAB.
Structured Movement
Navigating Up or Down, Forward or Backward
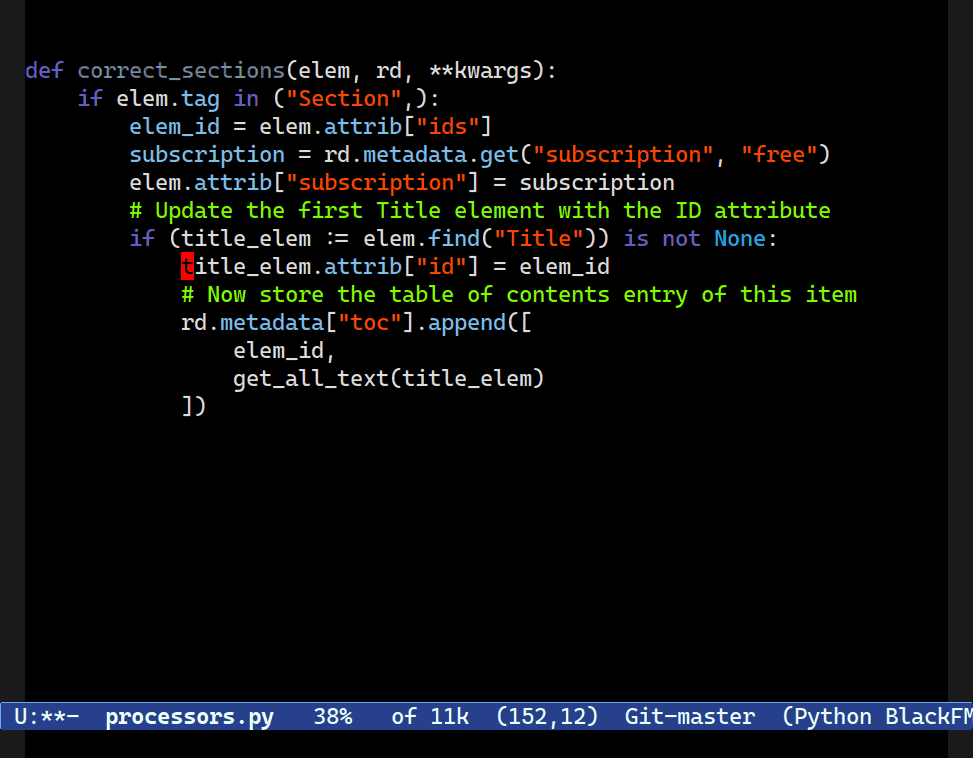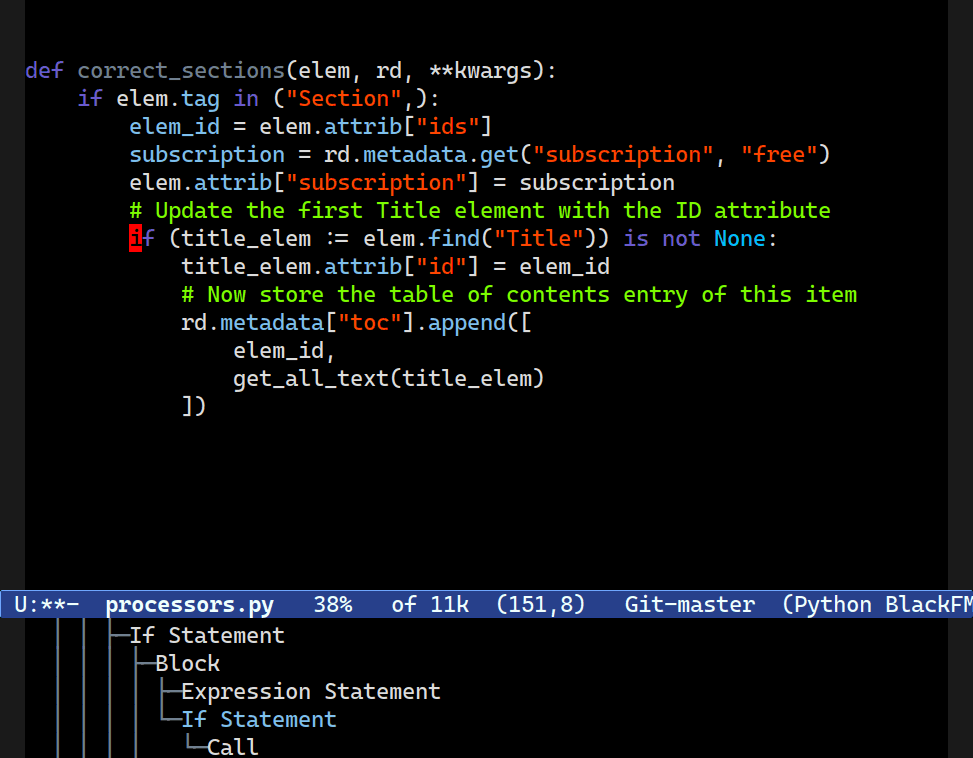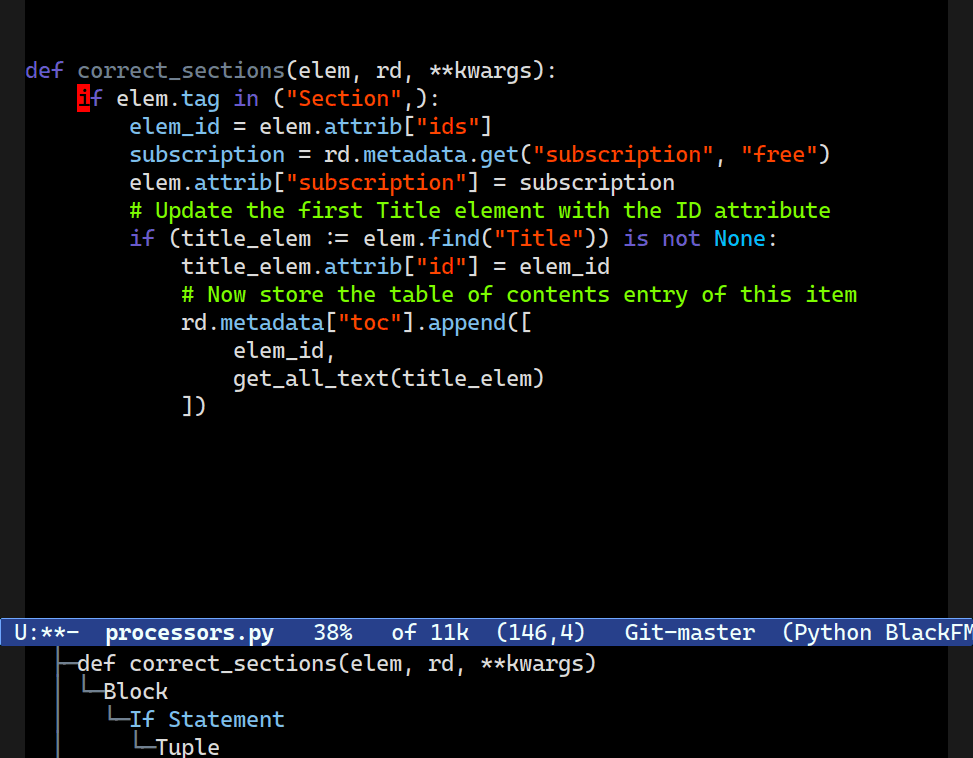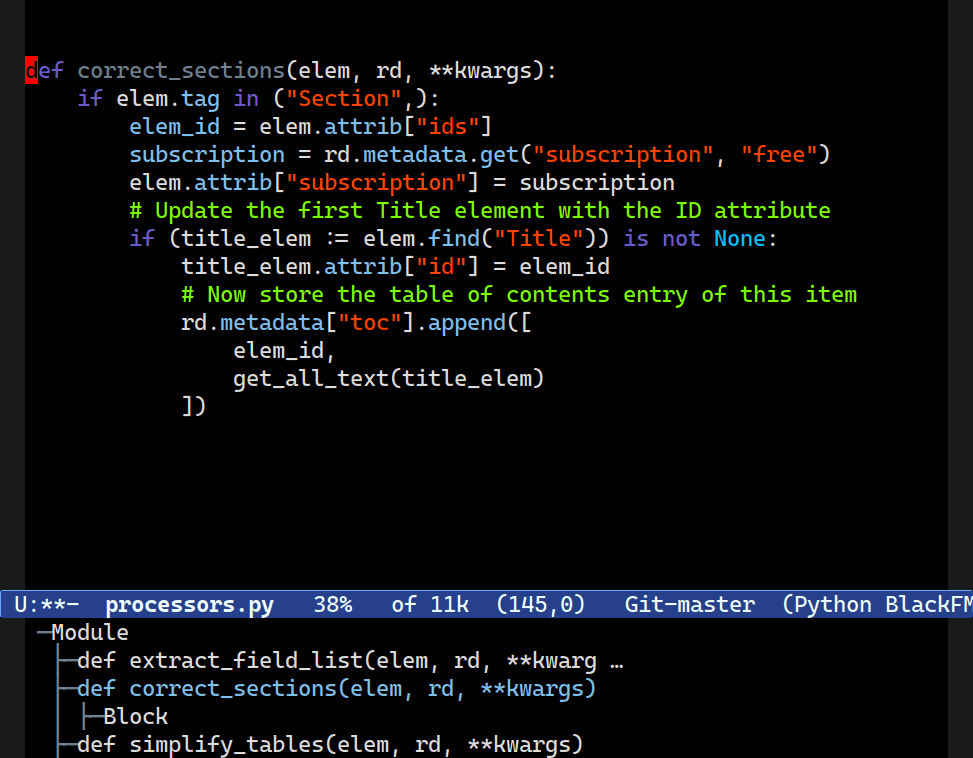
C-M-[d/u] is useful for navigating up or down structures of code. Combobulate is configured to move between useful clusters of code such as blocks in Python; JSX elements in JS/TS; and nested structures in YAML.One of the hallmark benefits of Emacs’s movement keys is their support for structured movement. They’re kinda-sorta designed for Lisp, but work well in a wide range of situations elsewhere too. Combobulate knows enough about the language to move to where you probably intend to go.
That means you can navigate up or down, or forward or backward, through parents, children and siblings with a set of intuitive key bindings that work consistently across all the languages Combobulate supports.
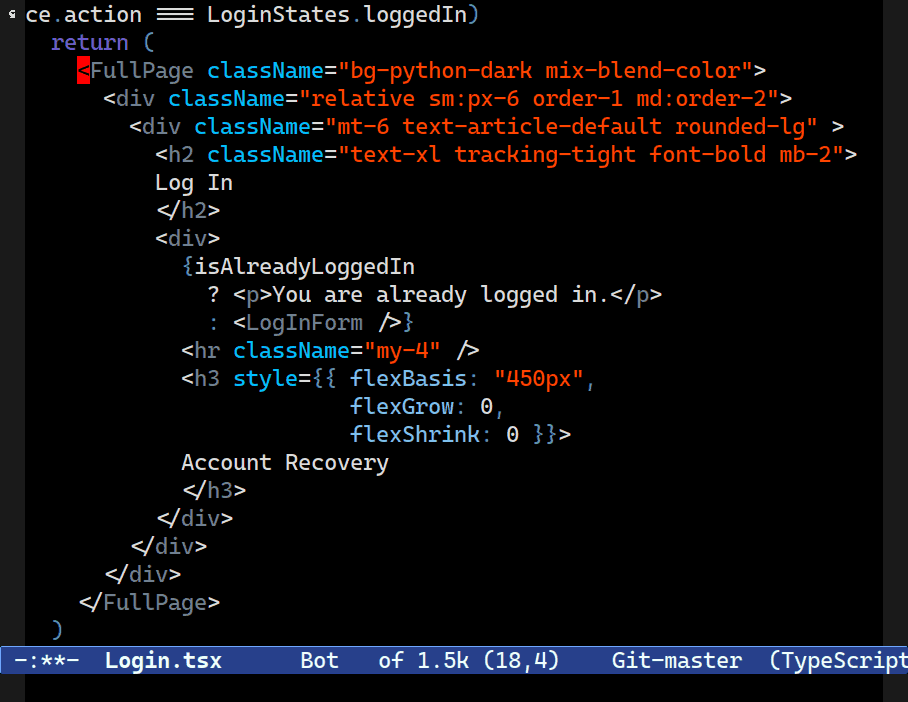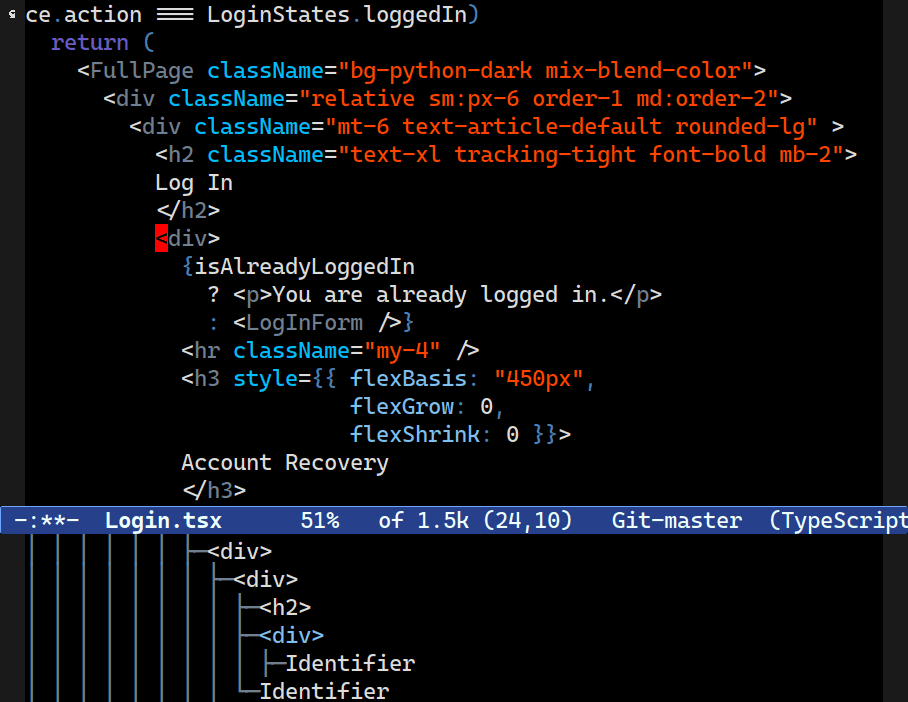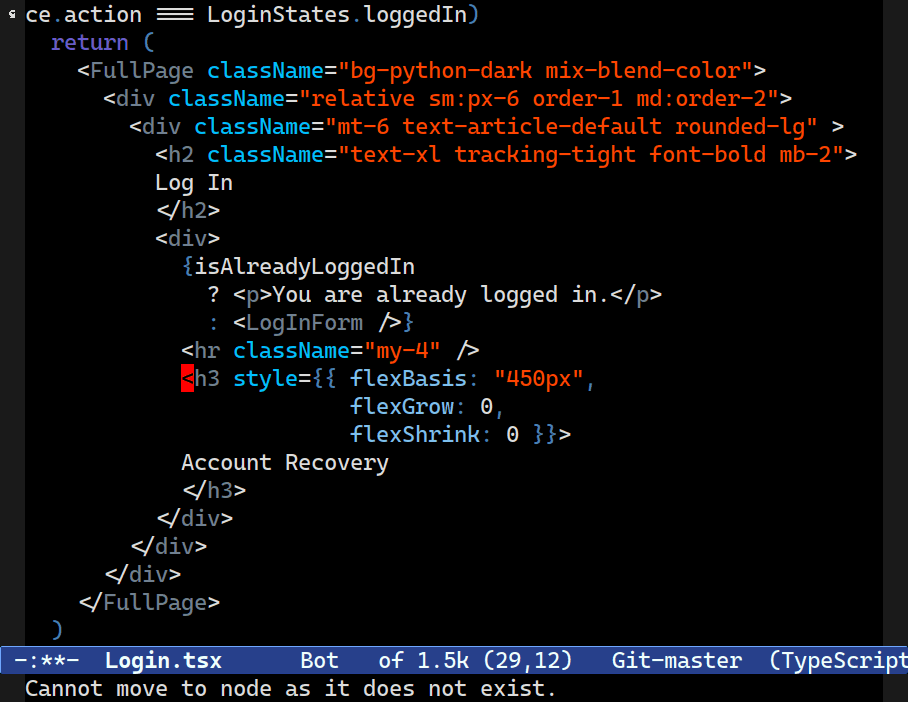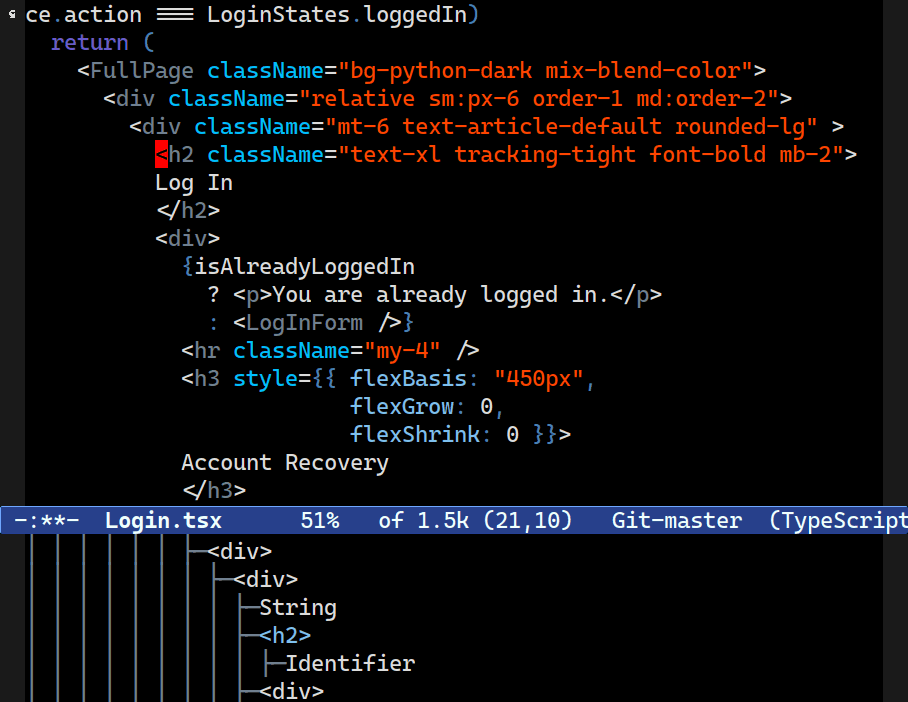
C-M-[n/p] now move between what a human programmer would intuit to be siblings. Combobulate keeps a list of node types that are commonly thought of as siblings to a programmer, even if structure of the tree would imply otherwise.Combobulate will not slavishly follow the exact tree structure, as it is far too granular and unintuitive.
Moving around is not always so obvious when you have a large and complex codebase. To make it easier for you to find your way around, Combobulate displays a quick tree-like minimap in the echo area when you invoke one of its movement commands.
As the gif above shows, you can move up or down list-like structures. In plain Emacs, C-M-u and C-M-d are designed to enter and exit any paired set of characters, like ( ... ) or [ ... ] — and Combobulate continues to do that, even if it is a orthogonal to where a naive hierarchical move would otherwise take you.
Sibling movement is a complex topic, even though it may appear to be one of the easiest. Concrete syntax trees have breadth and depth; navigating strictly using the tree is far too granular and counter-intuitive even to people with deep familiarity of a language’s tree structure.
Combobulate tries – emphasis, tries – to do the right thing and pick sibling nodes that you, the programmer, would logically consider to be siblings. That means it’ll correctly navigate by JSX elements and attributes; YAML pairs; function arguments; dictionary pairs and much more. It is of course configurable (with a little bit of elbow grease) but it is optimized for intuition and not ‘correctness’.
Marking and Moving to the beginning / end of defun
Moving to the start or end of function and class definitions is a surprisingly fraught topic. Combobulate swaps the existing C-M-a and C-M-e keys for its own. Additionally, you can configure combobulate-beginning-of-defun-behavior to control how Combobulate should navigate the topology of nested functions and classes.
Also, Combobulate treats arrow functions like a normal function definition, meaning the commands are now useful to Javascript and Typescript programmers, where nested arrow functions are common. (And of course you can customize this. You add other node types to the defun node list if you so desire!)
Likewise, C-M-h to mark defuns works in exactly the same way.
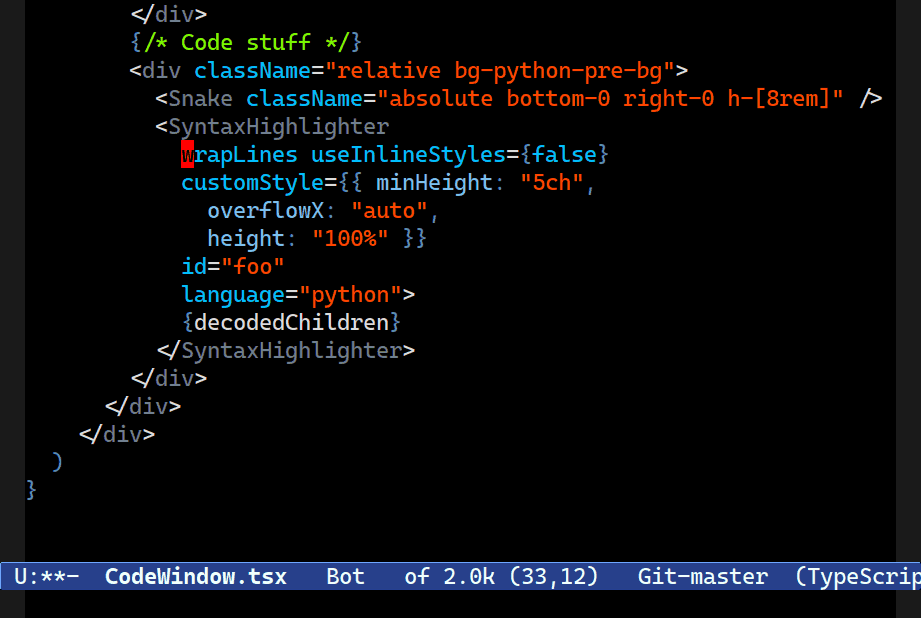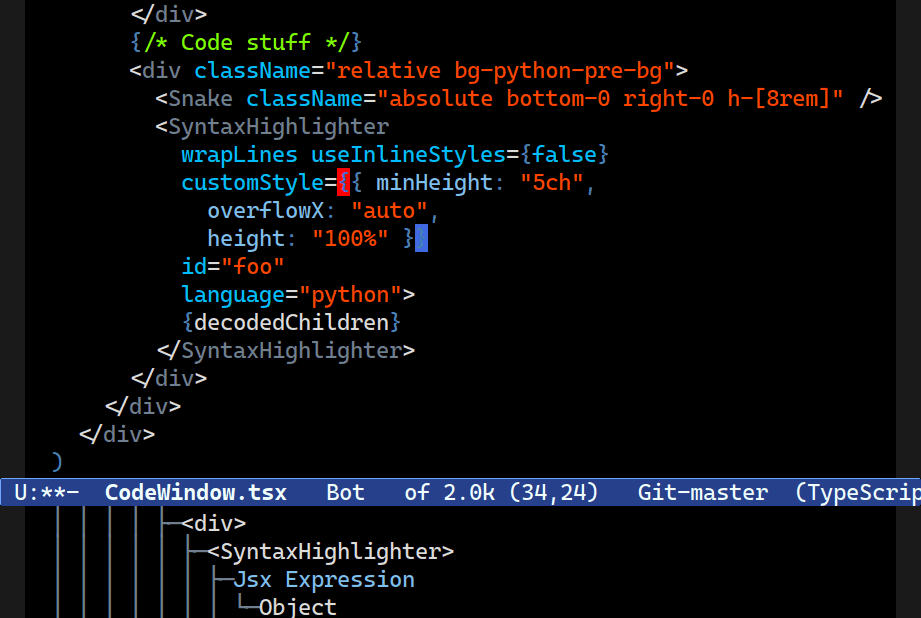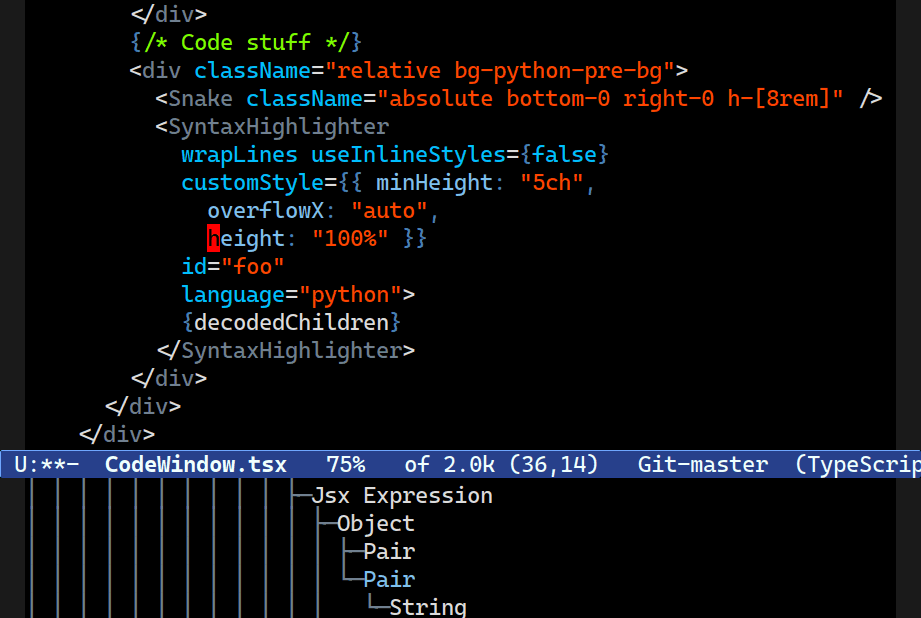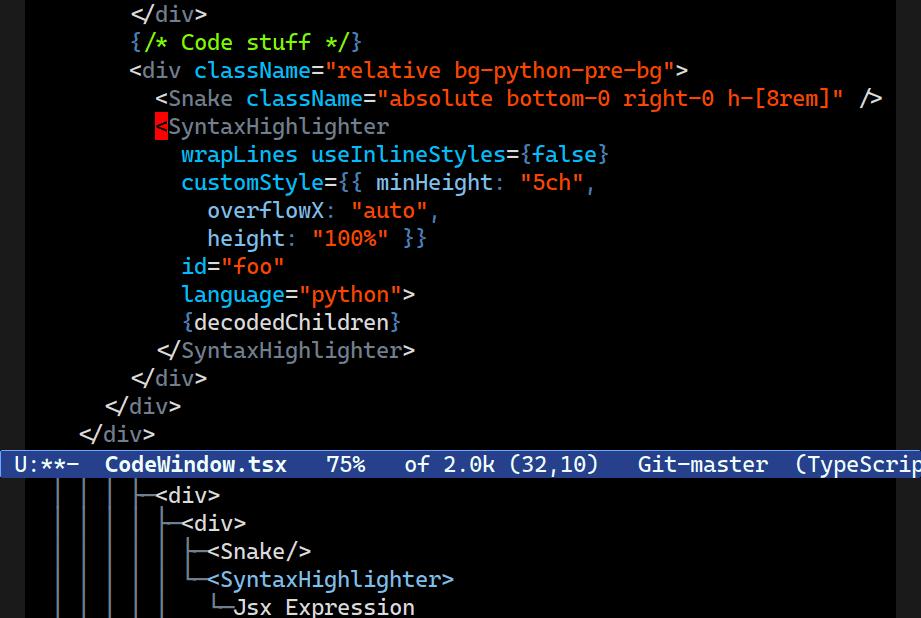
Expand Region
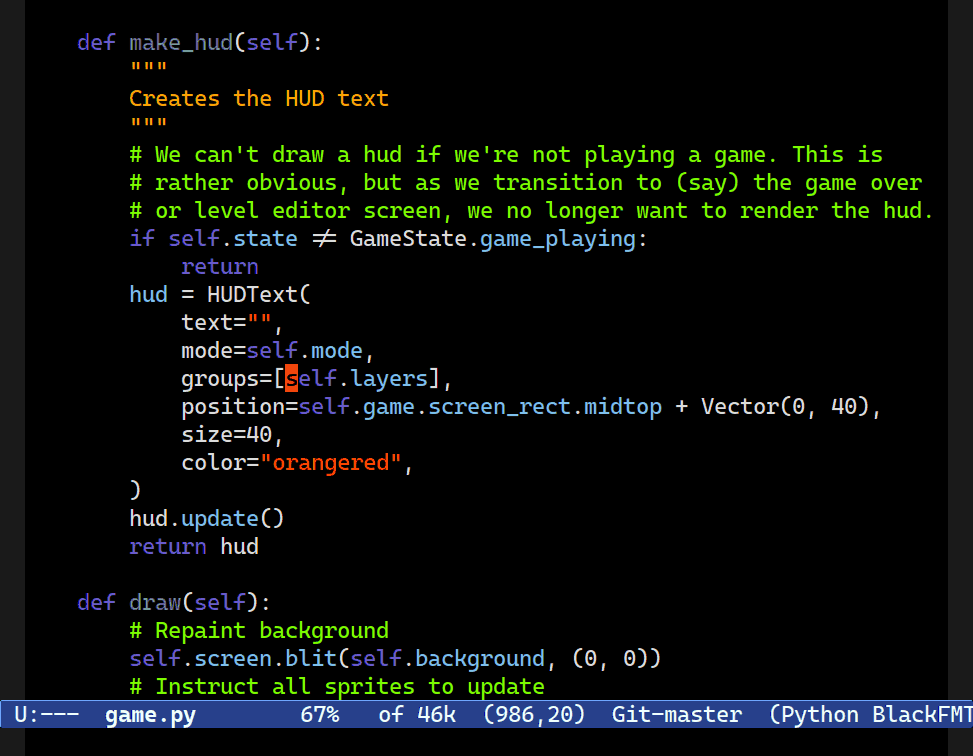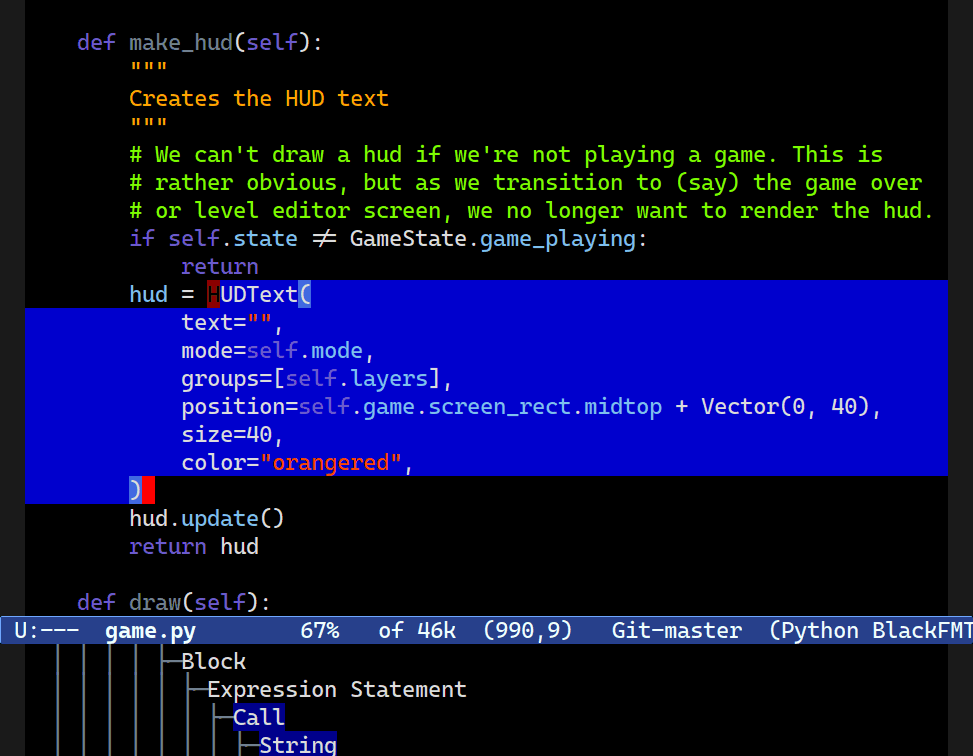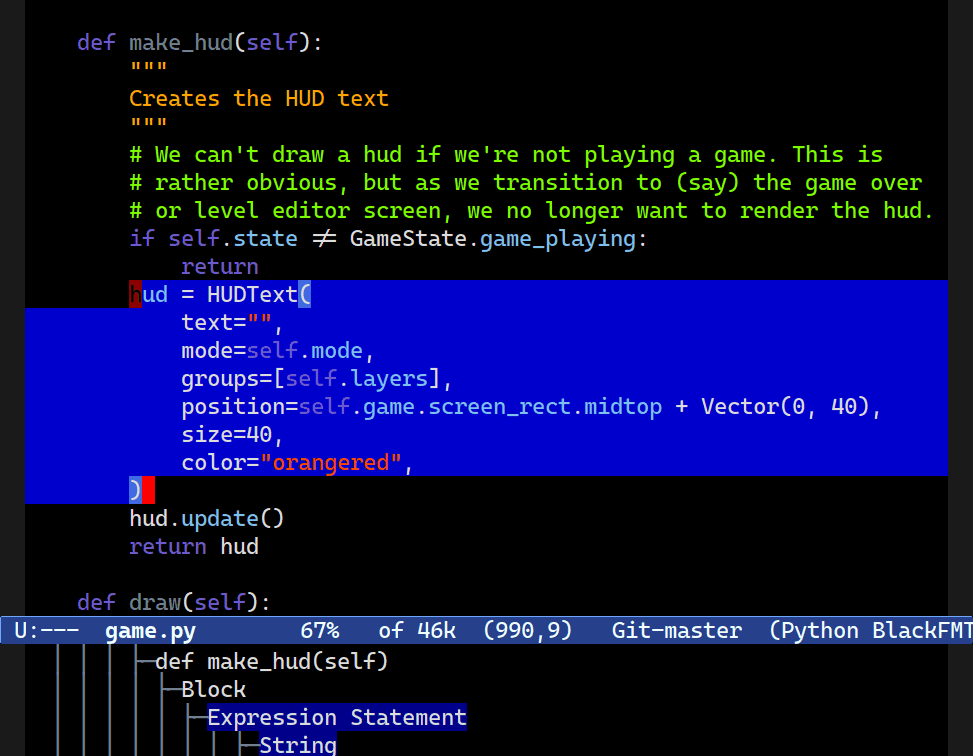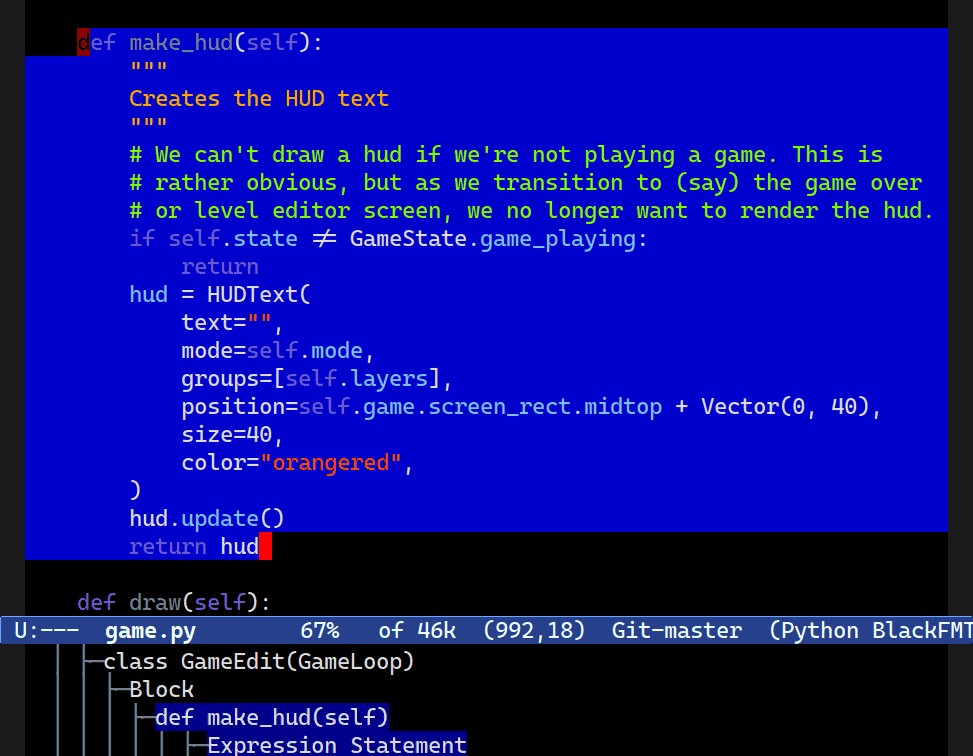
M-h now expands your region, one logical node at a time. Combobulate's expand region command extends to ever-larger tracts of your code.Combobulate will attempt to pick the next logical node to mark when you press M-h. Subsequent presses extends the marked region: Combobulate will extend the point and mark to ever-larger tracts of code.
Moving by S-Expression
Combobulate retains the existing behavior of C-M-f and C-M-b (and by extension, C-M-t and C-M-k.) But it’s also made to operate on select node types that the existing sexp machinery would otherwise misinterpret. Expect it to behave in much the same way as you’re (probably) used to. Combobulate now keeps a rather short list of nodes that it will treat as an s-expression when your point is in the right place. Everywhere else, it defaults to the normal behavior.
Conclusion
This first “proper” release of Combobulate is the culmination of months of work and experimentation – more of the trials and tribulations of that to follow in another article – and I feel it’s at a pretty good state. There’s much more to do, of course, as Combobulate only scratches the surface of what is possible. There are bugs to fix and features to add. (If you’d like to help, then by all means start by adding more language support!)
The biggest issue is that Combobulate does not modify the tree when it edits code. It uses a number of hacky workarounds. That is not a good, long-term strategy, but there is a really good reason why it doesn’t “modify” the tree (and again, more on that in future article.) Nevertheless, caveats aside, I find the improved editing and movement immensely helpful during my development, and I’m sure you will find it useful too.
If you haven’t already, head on over to Combobulate’s github page and download it. You’ll need Emacs 29 compiled with tree-sitter support for it to work though!

